
我觉得我需要学习python
(我想要成为AI大师)
快捷键:
1 | Ctrl + L #选中一行 |
Day-1 8.4
输出:
,只是起到给你一个空格,不是链接:

链接是靠 f (字符串流)
1 | print(f'我是{变量}') |
数字:

字符串特殊输出:
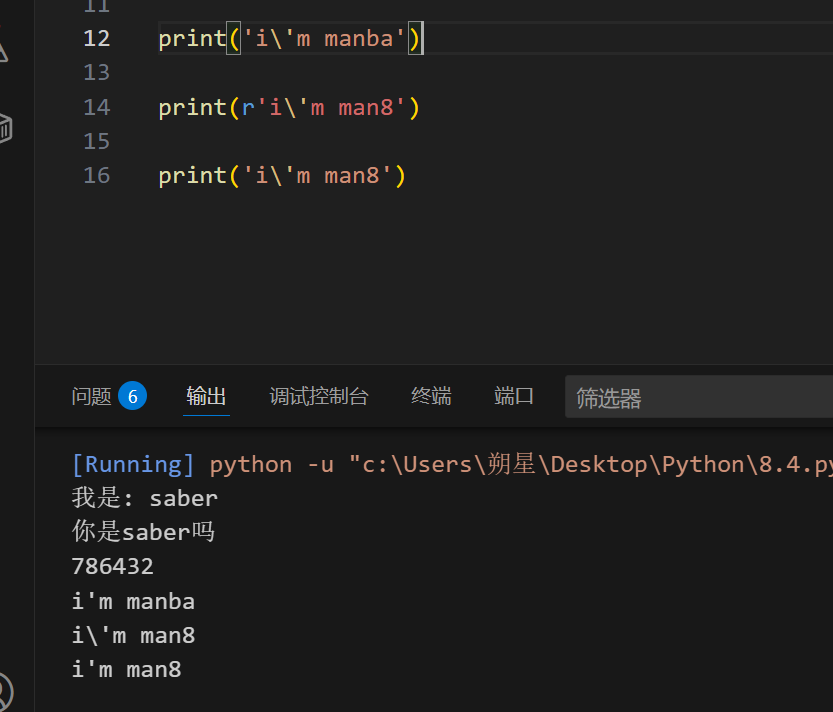
1 | print('i\'m manba') |
一旦输入 r 就会取消转义性质:
[ r 表示原始字符串(raw string)]
1 | print(r'i\'m man8') |
失去转义性质
\t:水平制表符(Horizontal Tab)
会自动对齐:
整除://
1 | print( 38//5 ) |
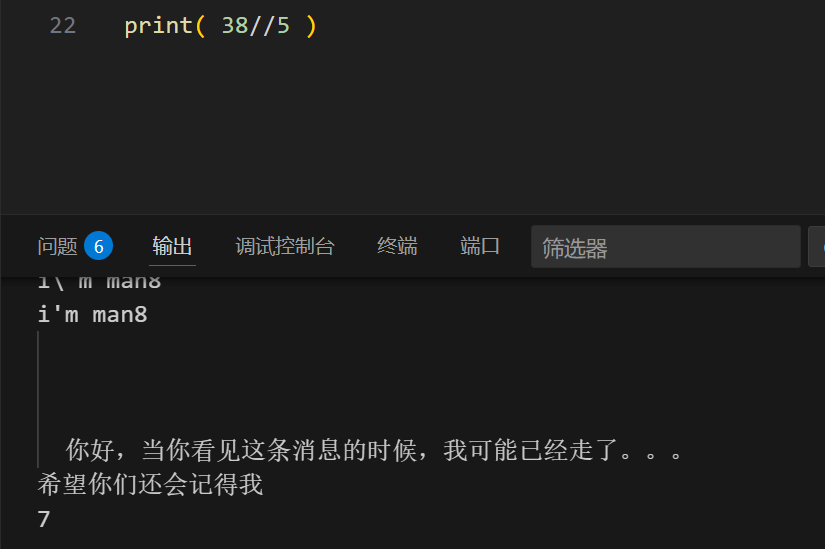
即使结果是7.6 还是指保留了7
编码:

Unicode:身份证

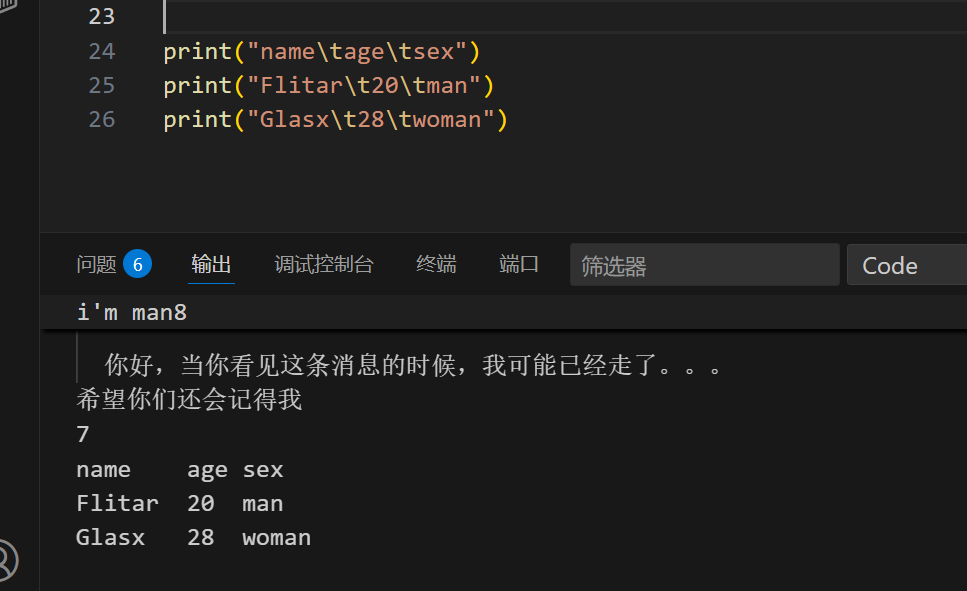
长什么样子:
1 | print( '\u4e2d\u6587') |
具体:

UTF-8:传输与表达:
转化过程:
1.确定字节:

2.拆为二进制并且组合:

得到编码的函数:
1 | print(ord("中")) #一次只能一个字符 |
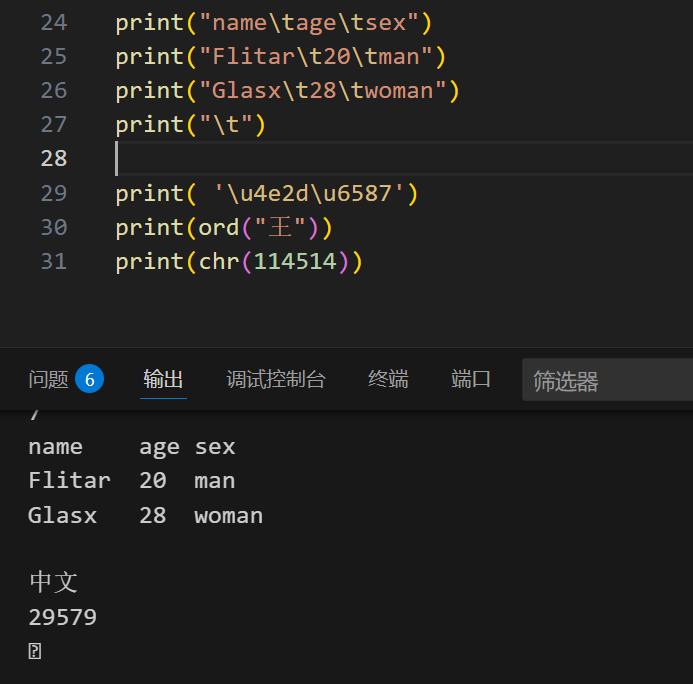
感觉 \t 效果比 \n 好
字节串和字符串互相转化:(utf-8的转化)
1 | print(b'\xe4\xb8\xad\xe6\x96\x87'.decode("utf-8")) #解码 |
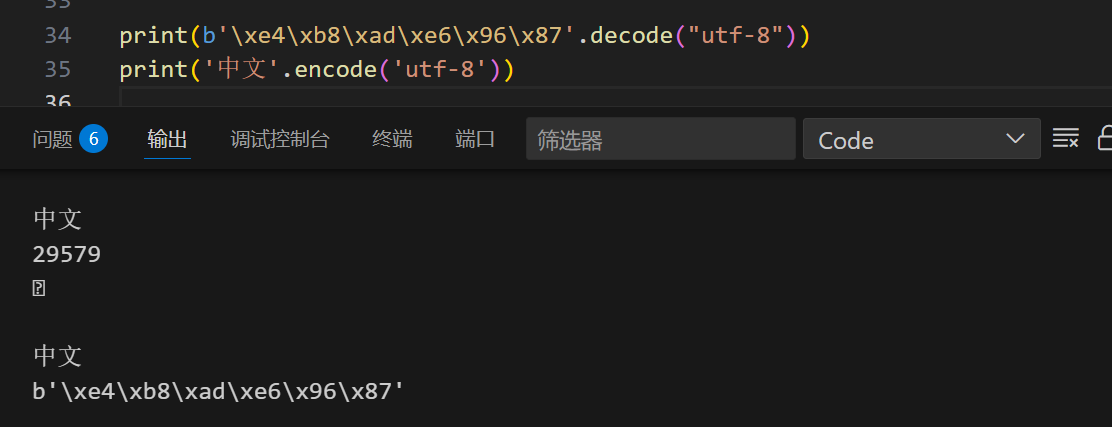
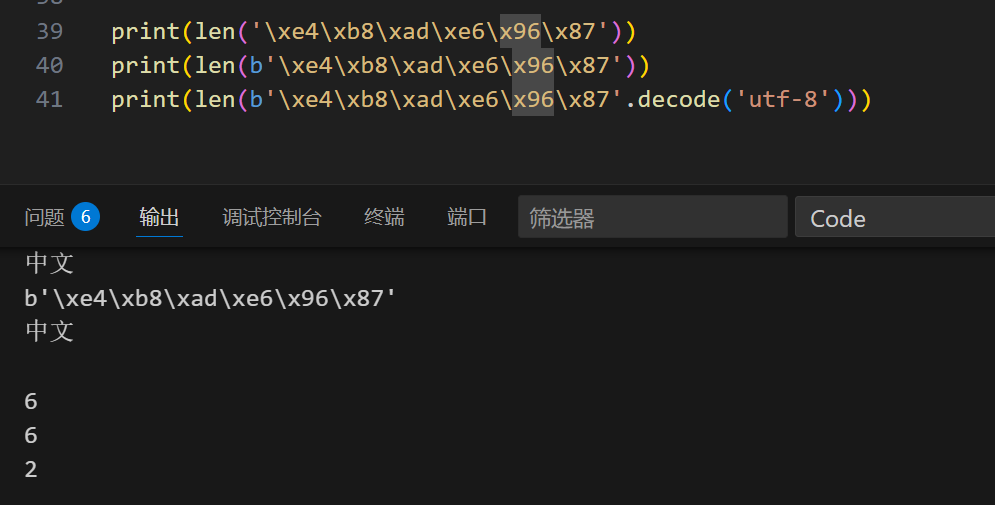
补充:len 长度函数:
1 | len('\xe4\xb8\xad\xe6\x96\x87') |
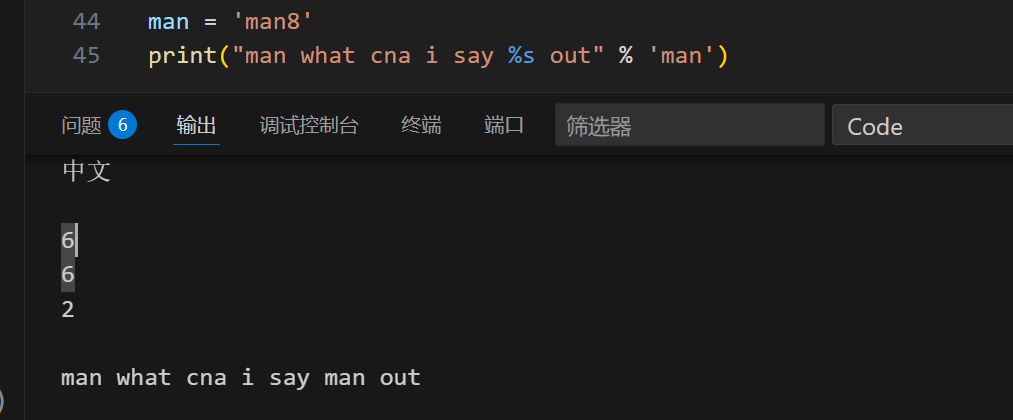
与C类似却不同的占位符:
1 | man = 'man8' |
却输出man 而不是man8:
1 | man = 'man8' |
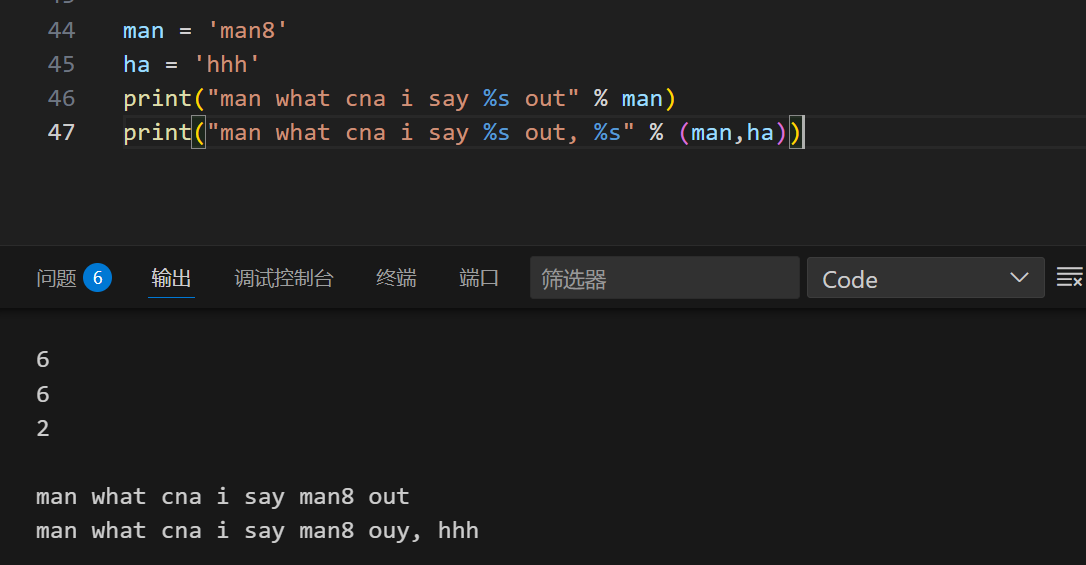
别样写法:
1 | print(f'man what can i say, {man} out') |
List (列表):
1 | name = ["man","man8","out"] |
类似于数组,但是可以存储各种各样的数据,字符串和数都可以
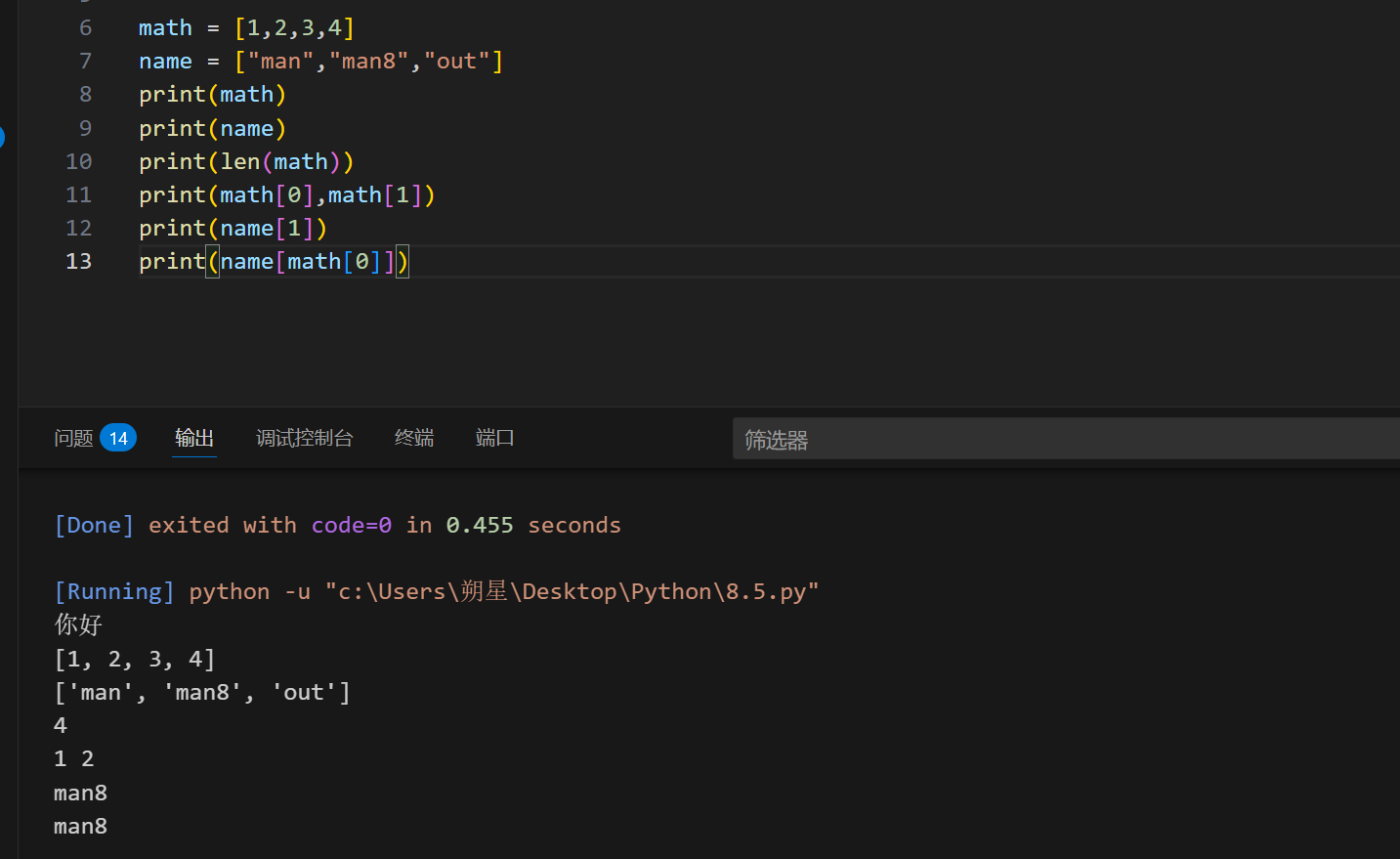
可以删减:
1 | math.append(5) #在最后一位加上5 |
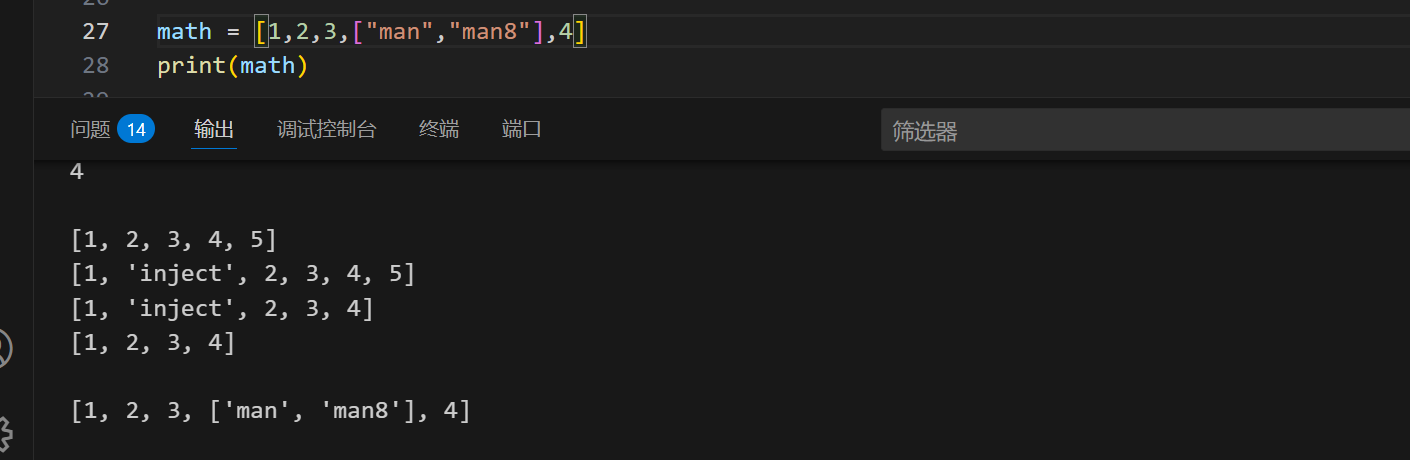
列表里面也是可以再接列表的:
1 | math = [1,2,3,["man","man8"],4] |
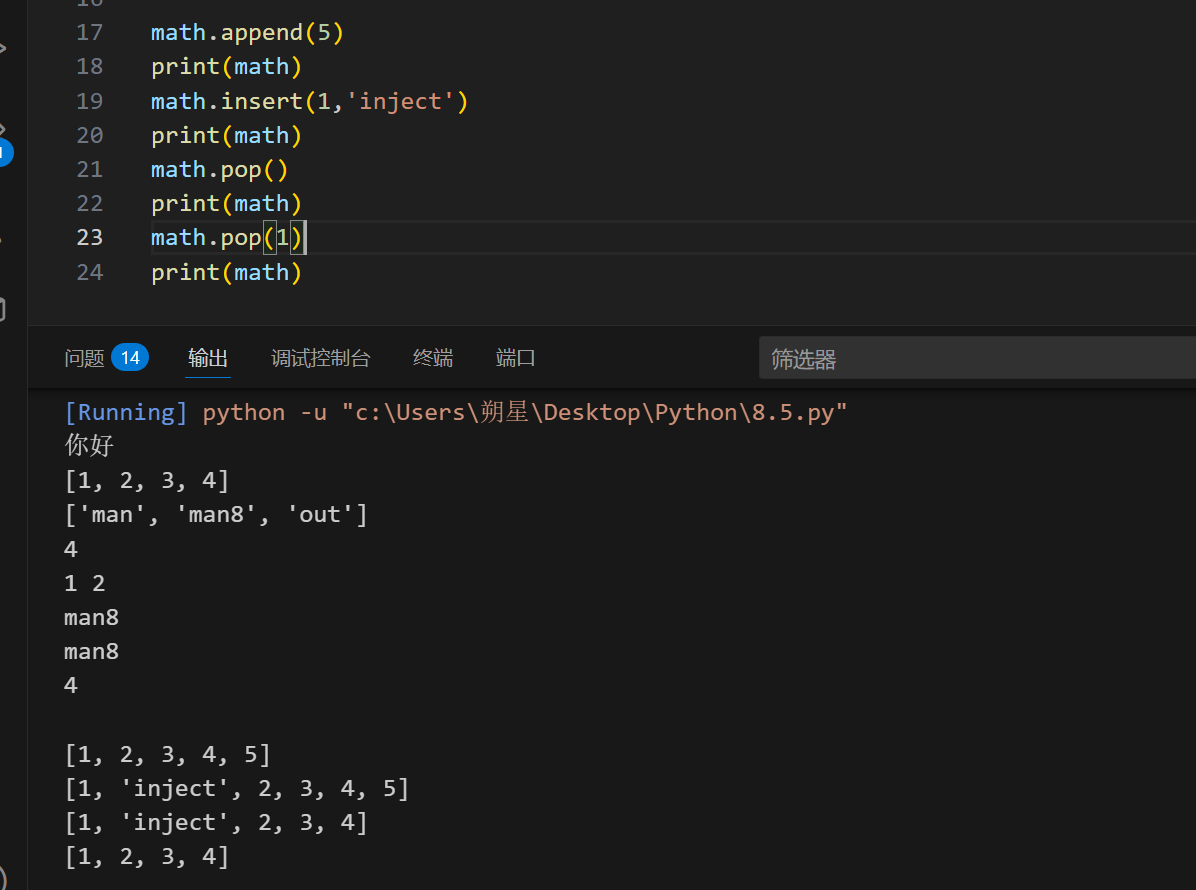
测试变量添加:
1 | math.append(1,name) |
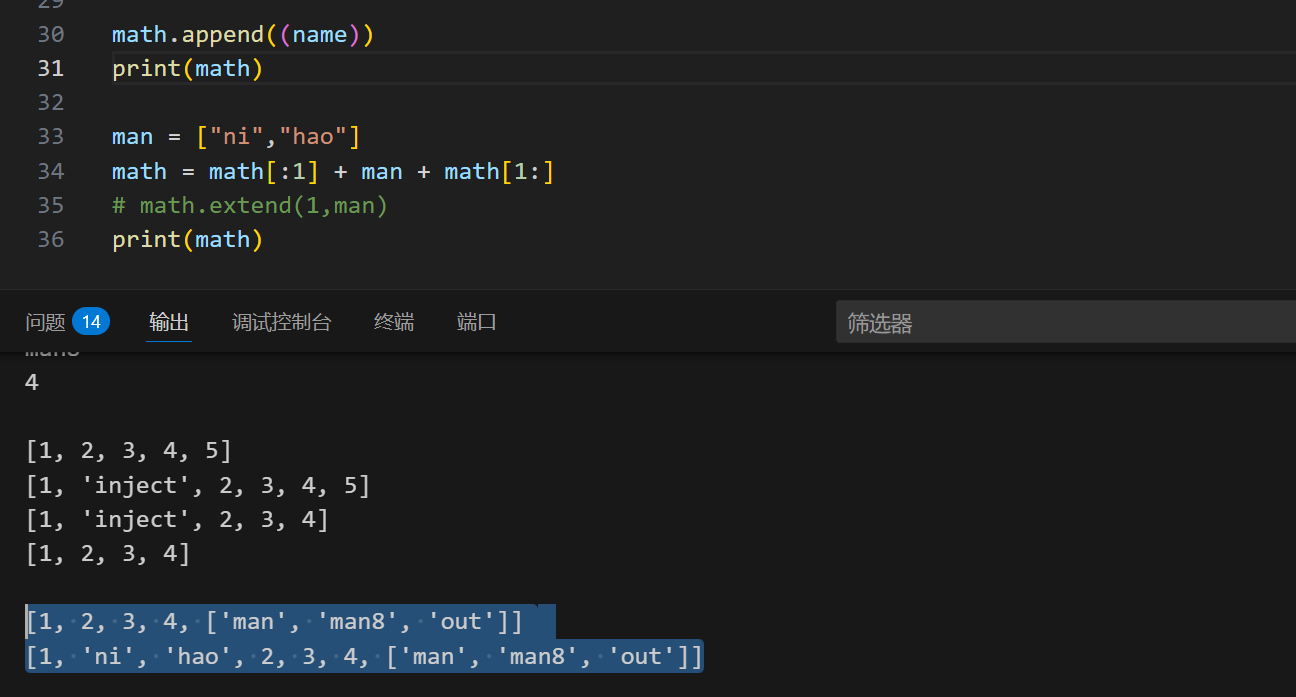
如果是二维列表呢?
1 | fff = [ |
tuple(元组):
就是数值不可变的列表,没有insert和extend函数
1 | ex_tuple= (1,2,3) #[]变为() |
元组的增删改查:
元组增加:
1 | tuple_1=(1,2,3) |
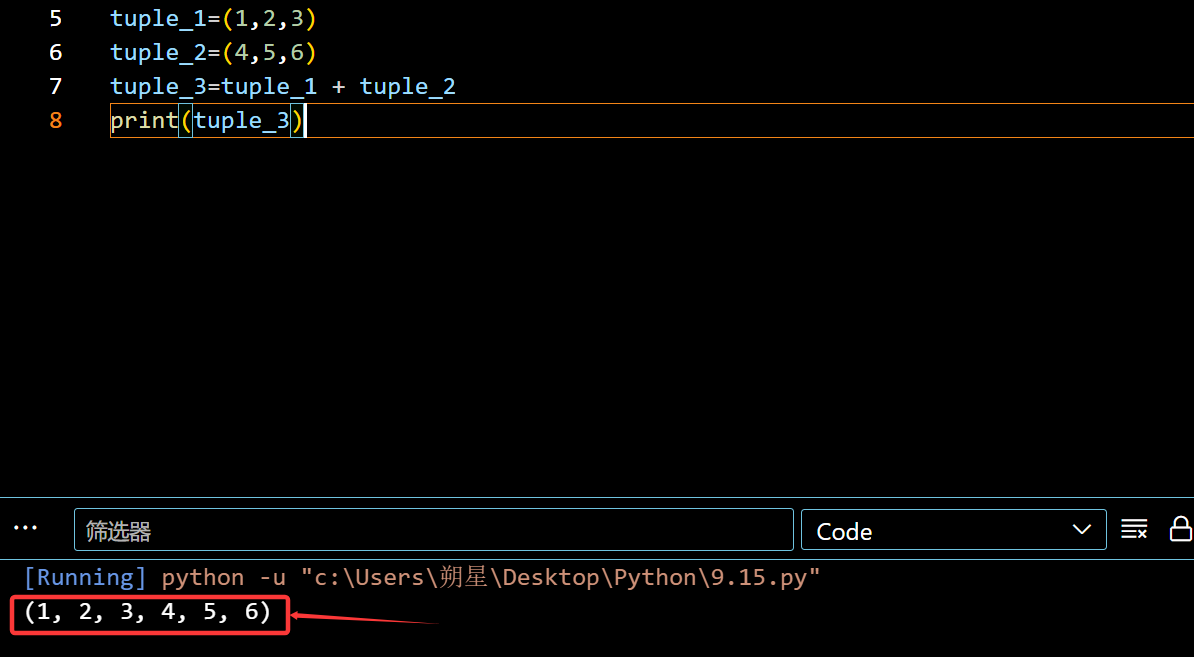
元组无法单独删除一个,想要在中间增加只能使用 []
元组查询:
1 | if 1 in tuple_3: |
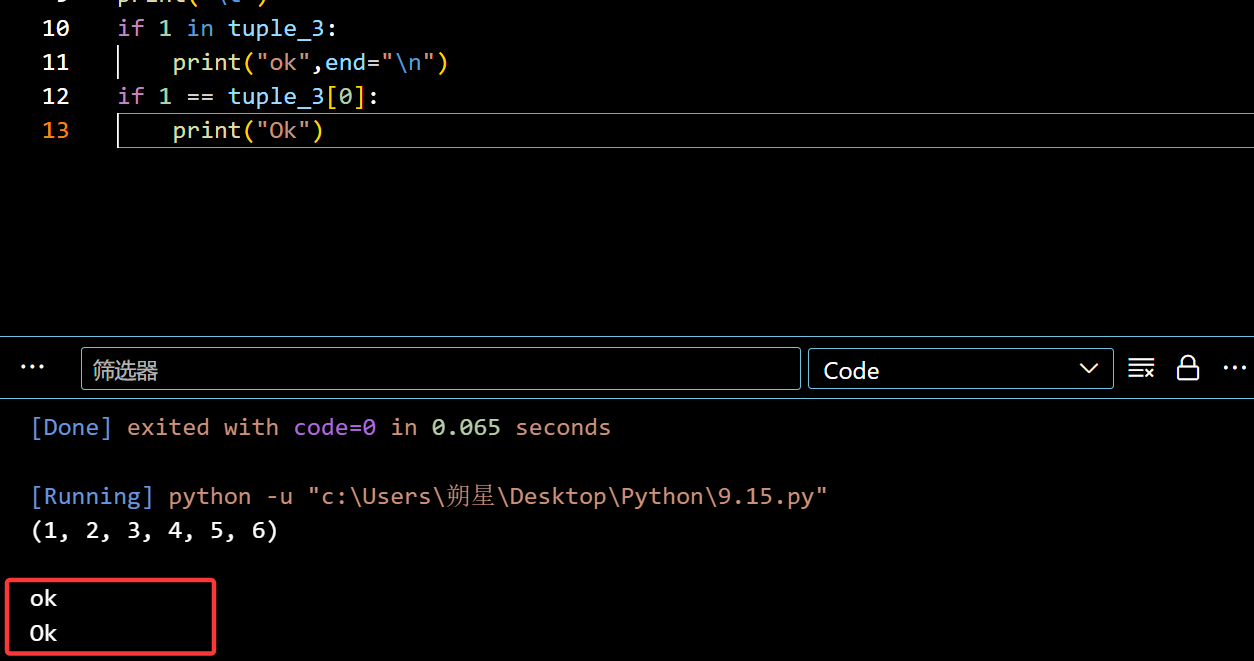
DAY-5 8.7
循环:
1 | if age <= 18: |
匹配:(match)
与whith相似
1 | scare = input("please inter you scare:") |
输入A只会匹配第一个:

1 | case x if x < "E": |
1 | case "A" | "B" | ....... |
与列表结合:
1 | case [1,2,3]: |
与type结合:
1 | # 匹配整数 |
循环:
1 | print(range(5)) #一般要和list一起组合利用才能 准确输出 |

1 | range(0,5)是代表从 0 到 4(不包括5) |
for循环:
1 | age = 1 |
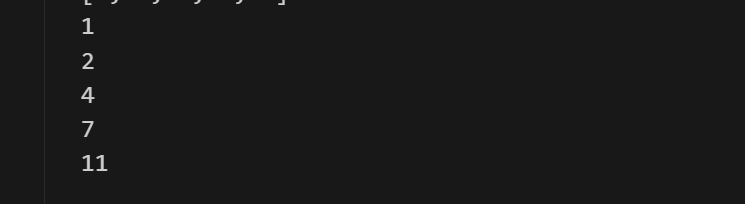
也可以与列表组合:
1 | name = ["man","man8","out"] |

while循环:
1 | while age < 20: |
break与continue
与C相似
1 | while x < 0: |
8.12
字典:(dict)
分为键-值(key-value),可自行添加:
1 | dict_1 = {24:'man','man8':8} |

判断是否在dict里面:
1 | print("老大" in dict_1) |
可以使用pop来删去:
1 | print(dict_1) |
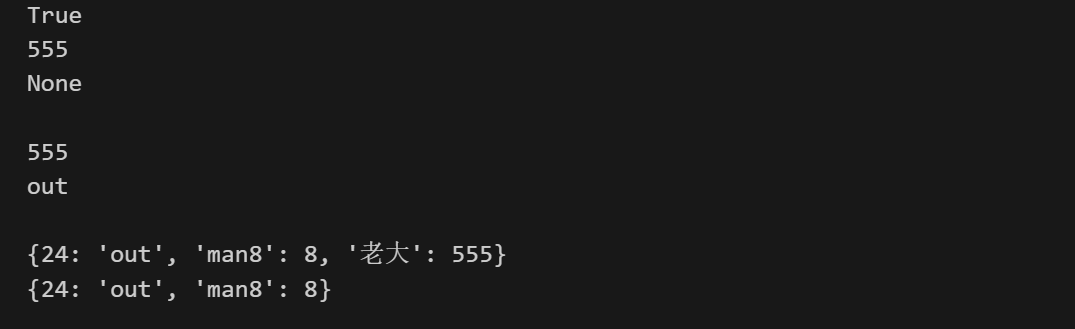
总结:
dict相比list,查找的更快,都是更占用空间
[!IMPORTANT]
dict根据key来计算value的存储位置,如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。这个通过key计算位置的算法称为哈希算法(Hash)
所以 key 的值是不可变的
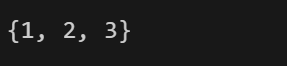
集合(set):
1 | {1,2,3} #就是set(集合),是不可重复的 |
增加与删去:(add remove)
1 | set_1.add("man") |

转化:
1 | aaa = set([1,2,3,3,3]) |

可以交集并集:
1 | bbb = {"out",1,2} |

总结:
1. 列表(list)常用方法
append(x):在列表末尾添加元素xextend(iterable):用可迭代对象的元素扩展列表insert(i, x):在索引i处插入元素xremove(x):删除第一个值为x的元素(不存在则报错)pop([i]):删除并返回索引i处的元素(默认最后一个)sort():对列表元素排序reverse():反转列表元素顺序index(x):返回第一个值为x的元素的索引
2. 字典(dict)常用方法
get(key, default):返回键key对应的值,不存在则返回defaultkeys():返回所有键组成的视图values():返回所有值组成的视图items():返回所有键值对组成的视图pop(key):删除并返回键key对应的值update(other):用其他字典的键值对更新当前字典
3. 字符串(str)常用方法
split(sep):按分隔符sep分割字符串为列表join(iterable):用字符串连接可迭代对象的元素strip():去除字符串首尾的空白字符upper()/lower():转换为全大写 / 全小写replace(old, new):替换字符串中的子串startswith(prefix):判断是否以指定前缀开头
4. 集合(set)常用方法
add(x):向集合添加元素xremove(x):删除元素x(不存在则报错)discard(x):删除元素x(不存在则不报错)union(other):返回两个集合的并集(等价于|)intersection(other):返回两个集合的交集(等价于&)difference(other):返回两个集合的差集(等价于-)
函数(9.2):
基础函数使用:
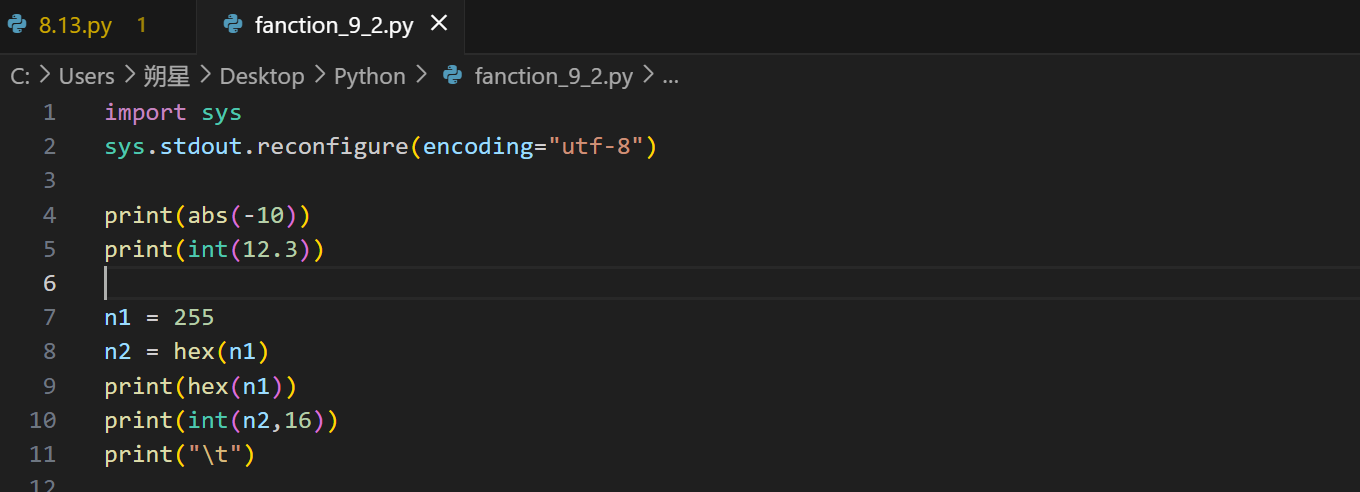
1 | n1 = 255 |
函数的基本格式:
1 | def my_abs(x): |
调用其他文件里面的函数:(文件名要符合变量命名规则)
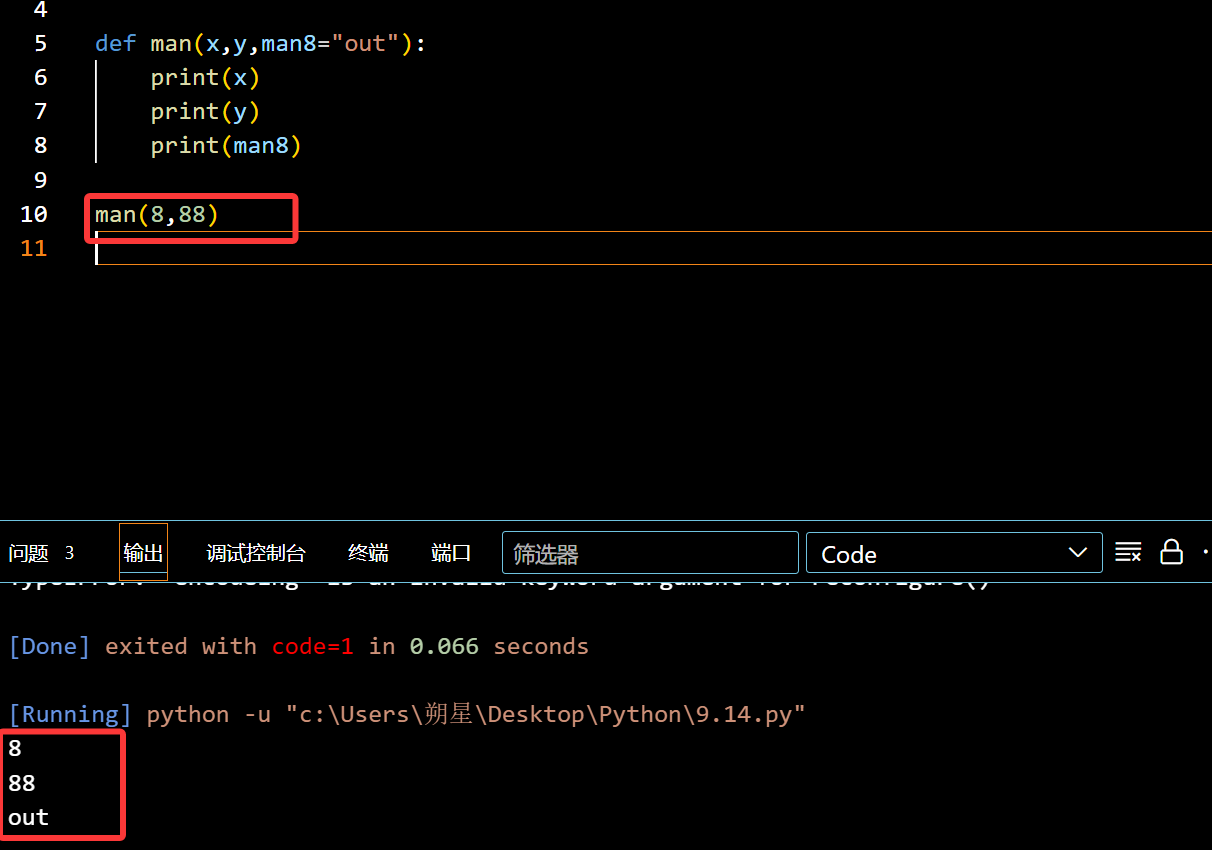
函数可以提前固定好某个变量的数值(9.14)
1 | def man(x,y,man8="out"): |
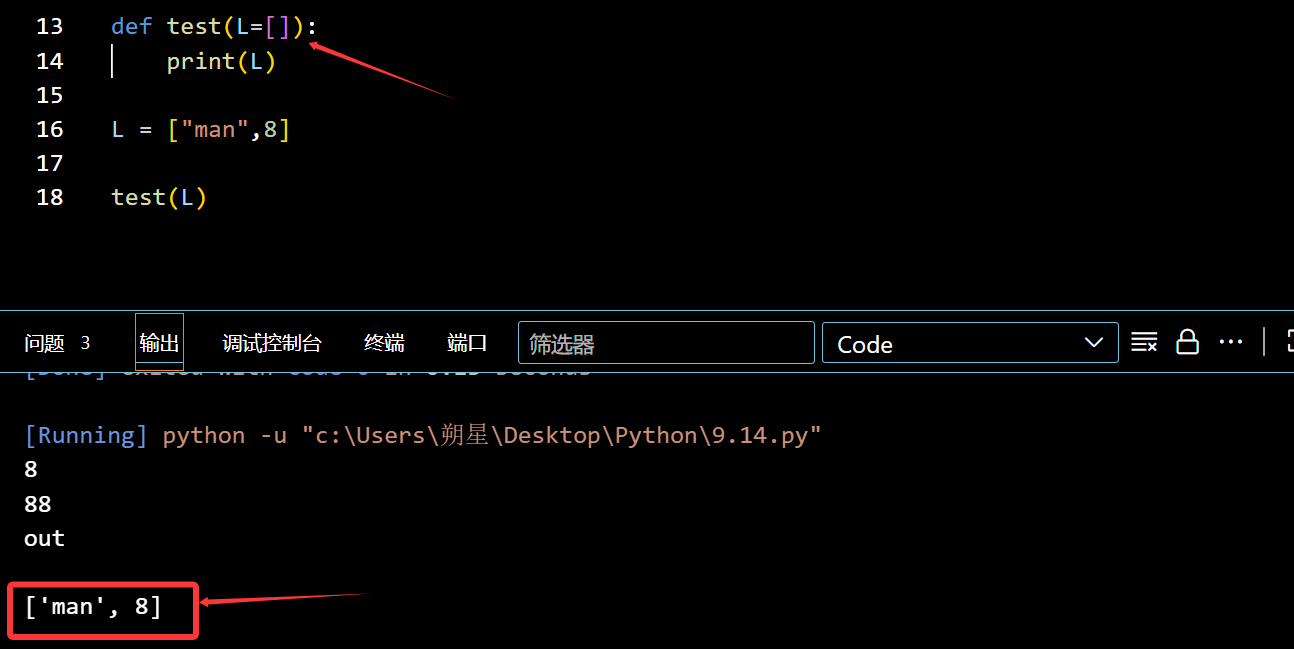
函数可以引入数列:
1 | def test(L=[]): |
函数与数列高级利用:
1 | def test_2(number): |
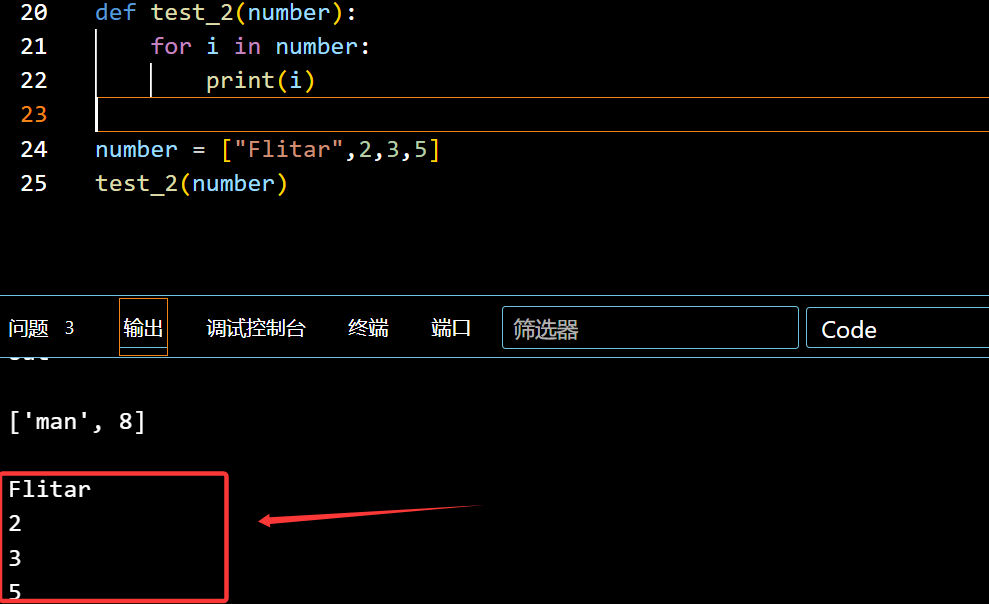
可输入元组:(加个*号)
1 | def test_3(x_1,*x_2): |
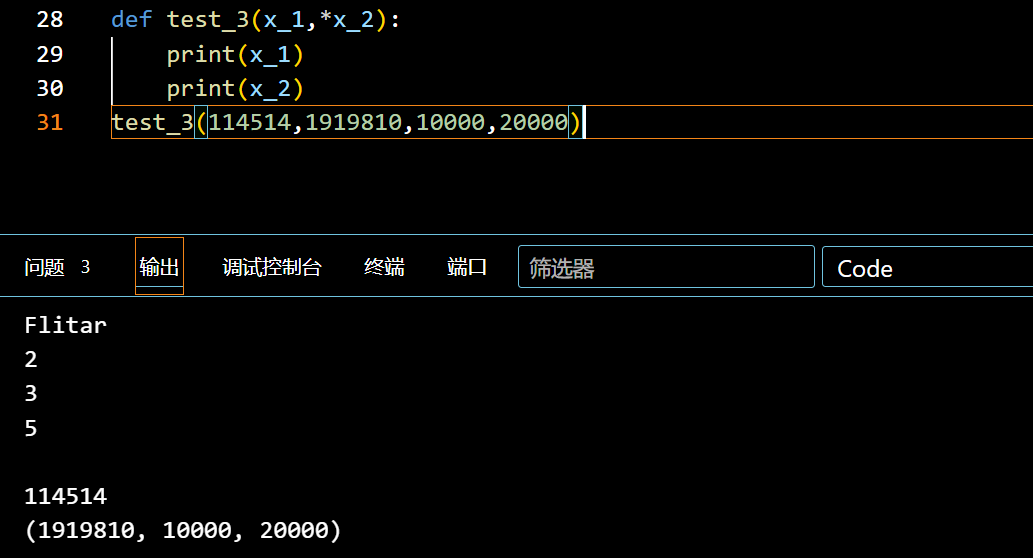
会发现后面的全部规划到了元组里
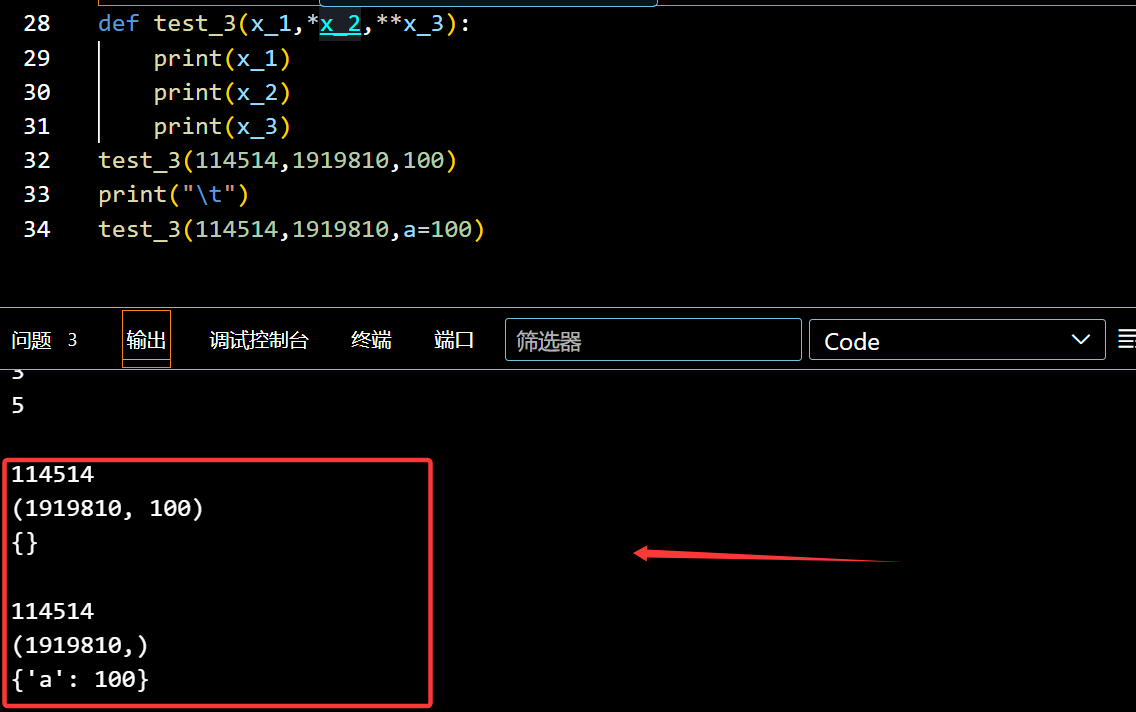
可输入字典:加**号
1 | def test_3(x_1,*x_2,**x_3): |
DAY ??(10/20)
都怪三角洲,浪费了我半个月时间,坏透了
高级特性 - 生成器(Generator)
补充:(特殊列表)
1 | L=[ a*b for a in range(1,5) for b in range (1,3)] |
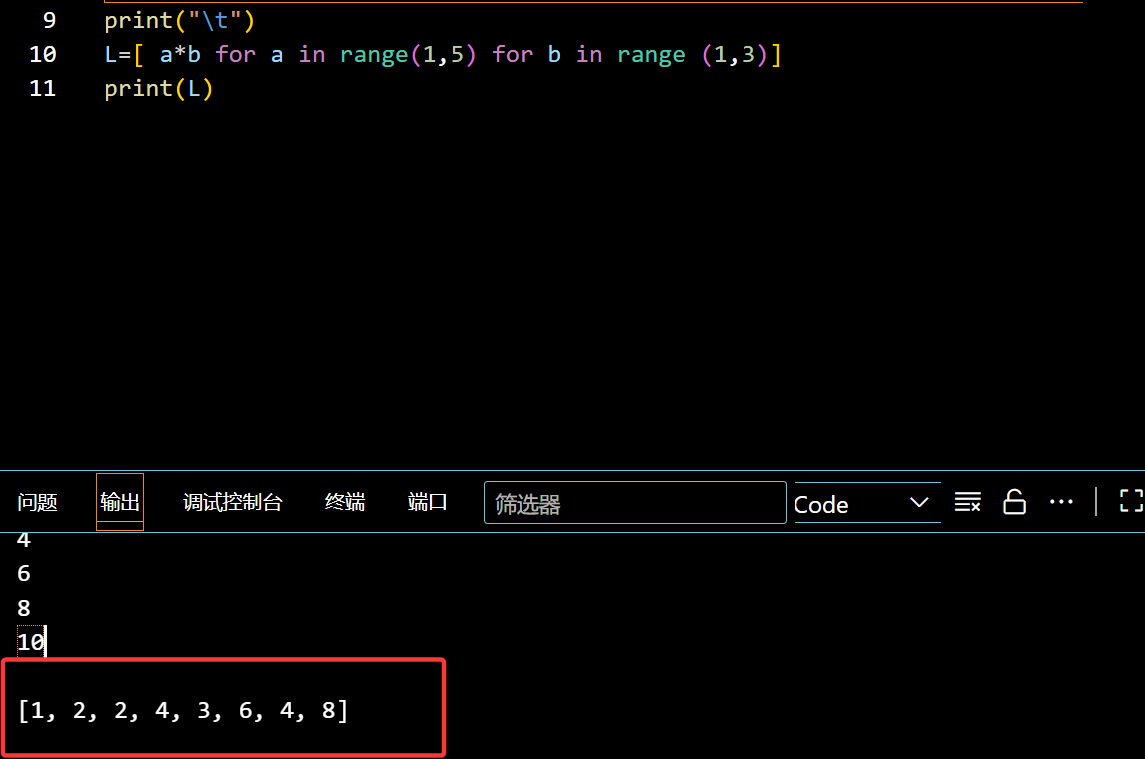
可以直接快速有效的生成 list
生成器:需要的时候调用就行
1 | L=( a*b for a in range(1,5) for b in range (1,3)) #把[]换为() |
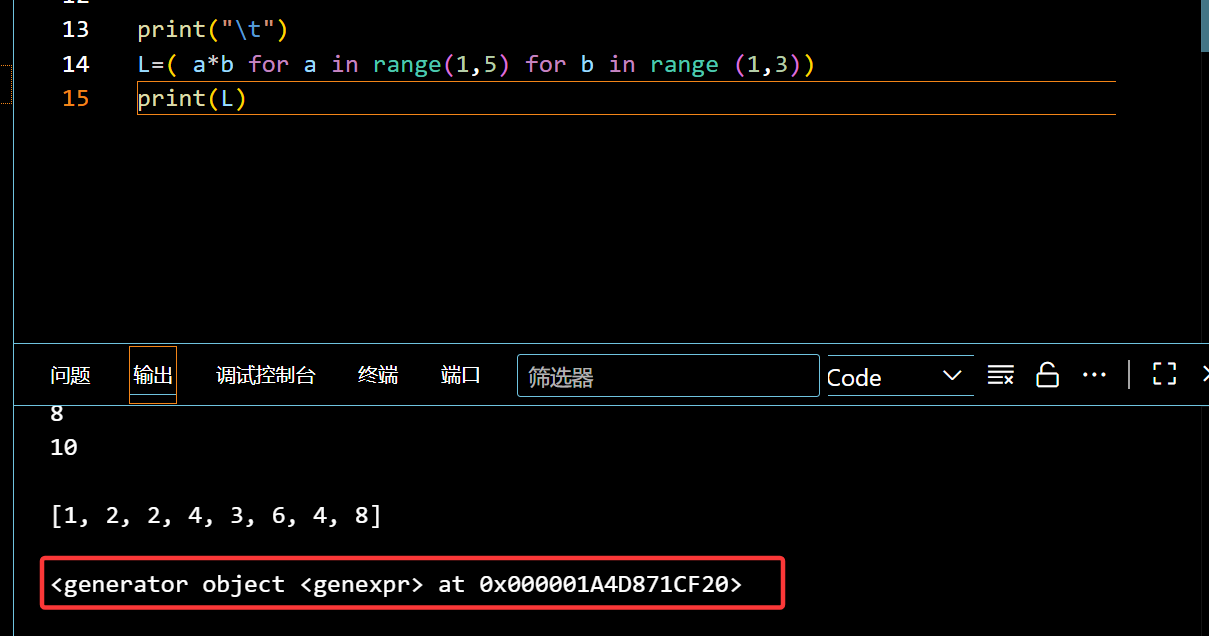
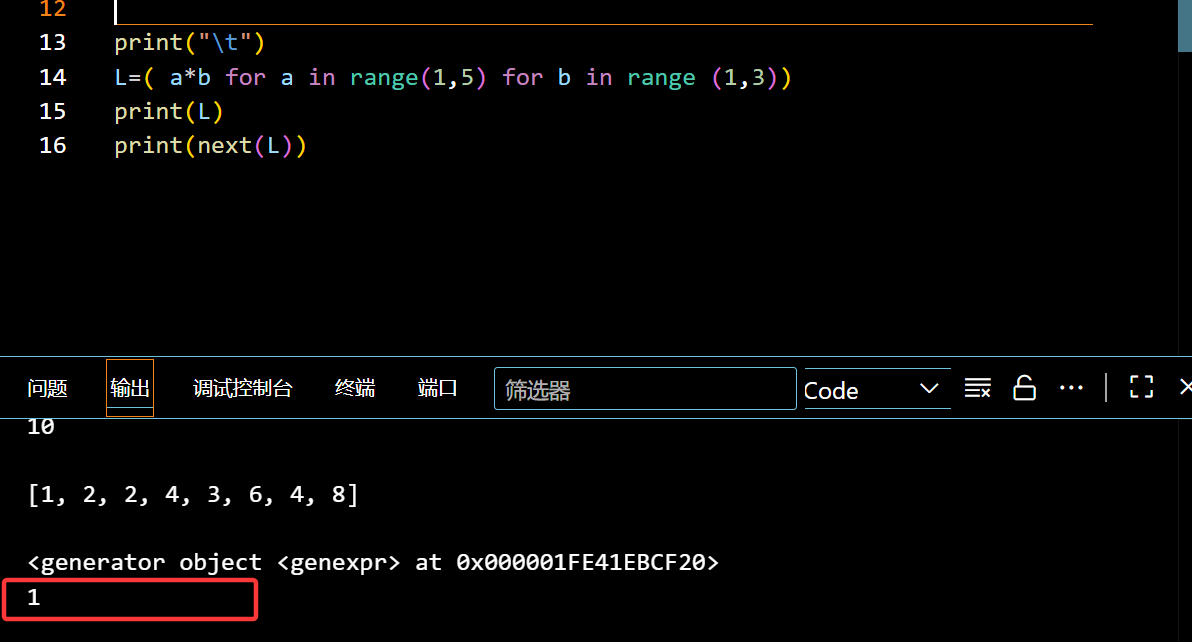
提前预定好位置,想要的时候就用next
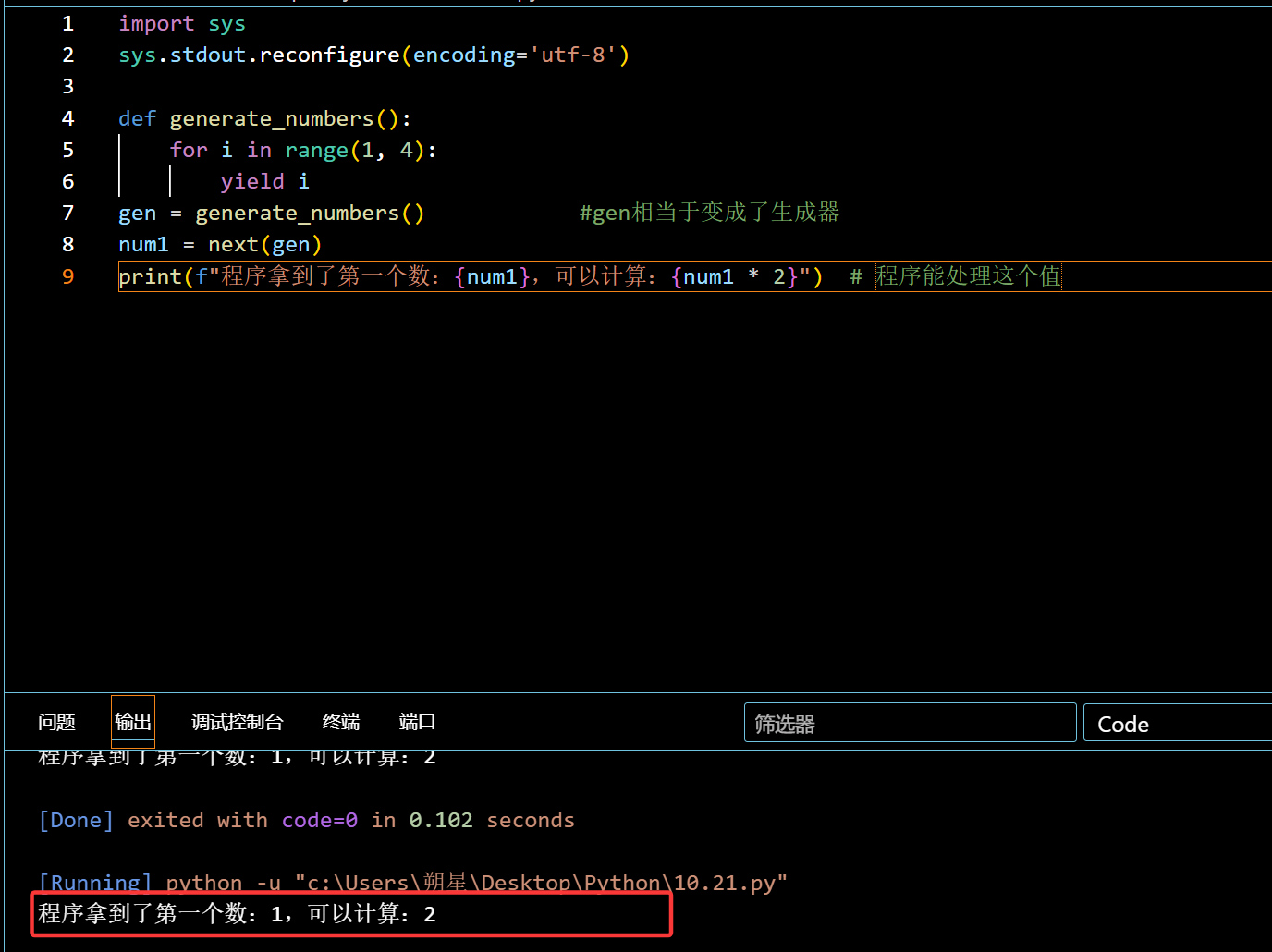
在函数中的调用(yield)
1 | import sys |
相当于提前预制菜。
可迭代和迭代器
可迭代:(Iterable)
list ,dict ,str 都是常见的可迭代,却不是迭代器.
迭代器:
可以被 next() 调用的就叫做迭代器(就是变成了生成器)
转化:
使用函数 iter() 进行转化:
1 | a = [1,2,3] |
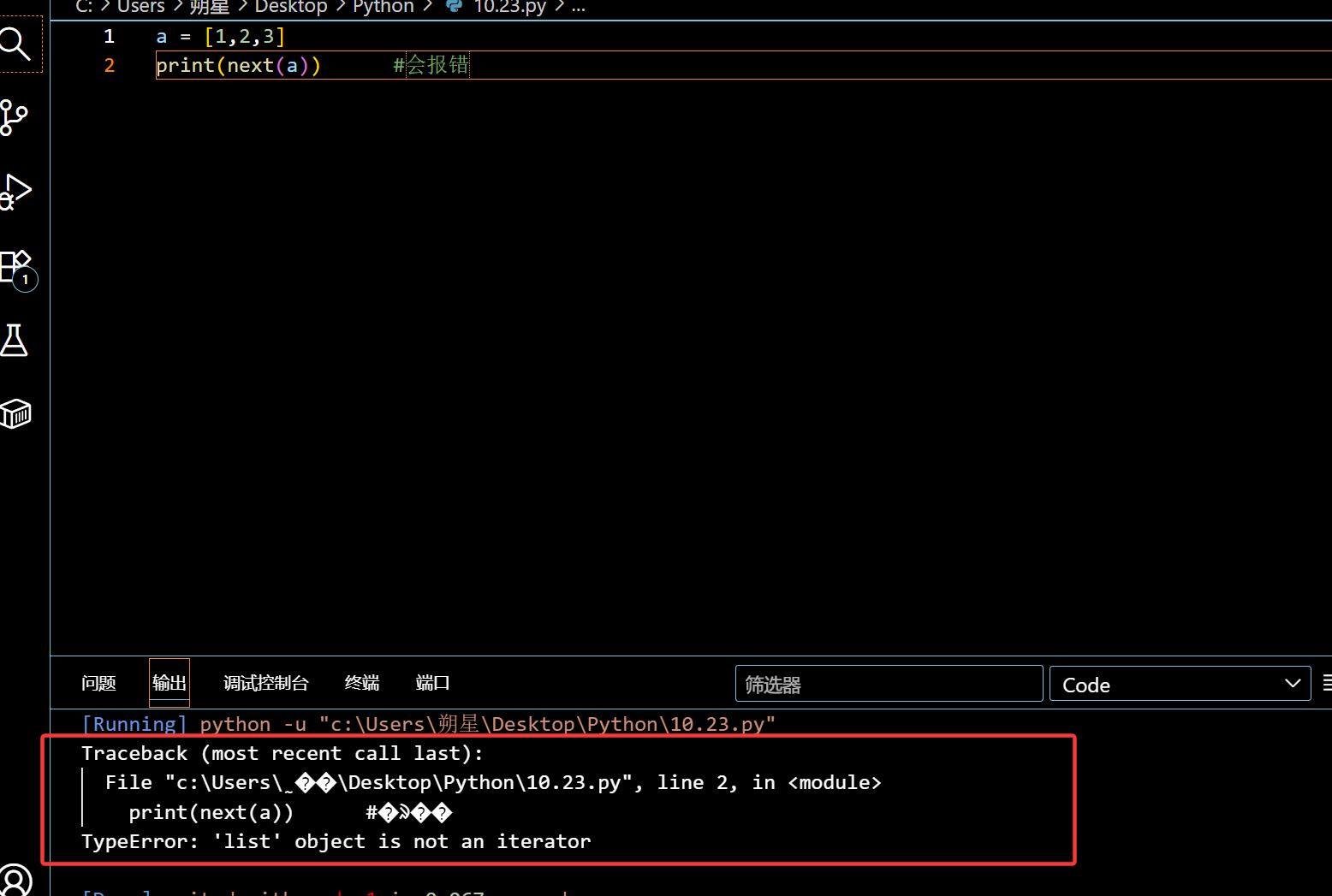
1 | a = [1,2,3] |
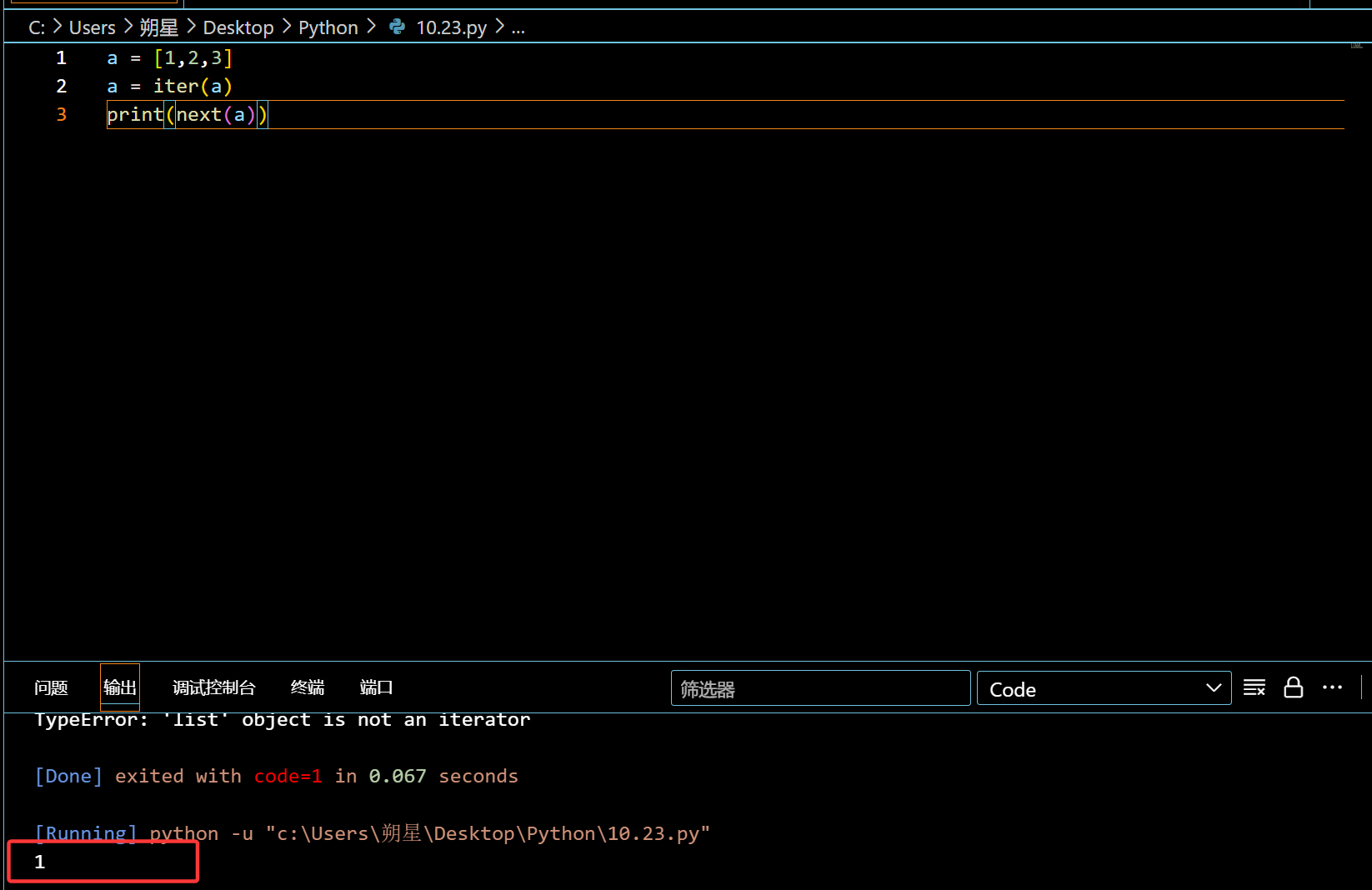
成功转化为迭代器。(和生成器一样,都是用于节省空间的)
高阶函数:
基础概念:就是把函数当作变量来使用。
内置函数可以被赋值和赋值给他人(绝对值abs为例子)
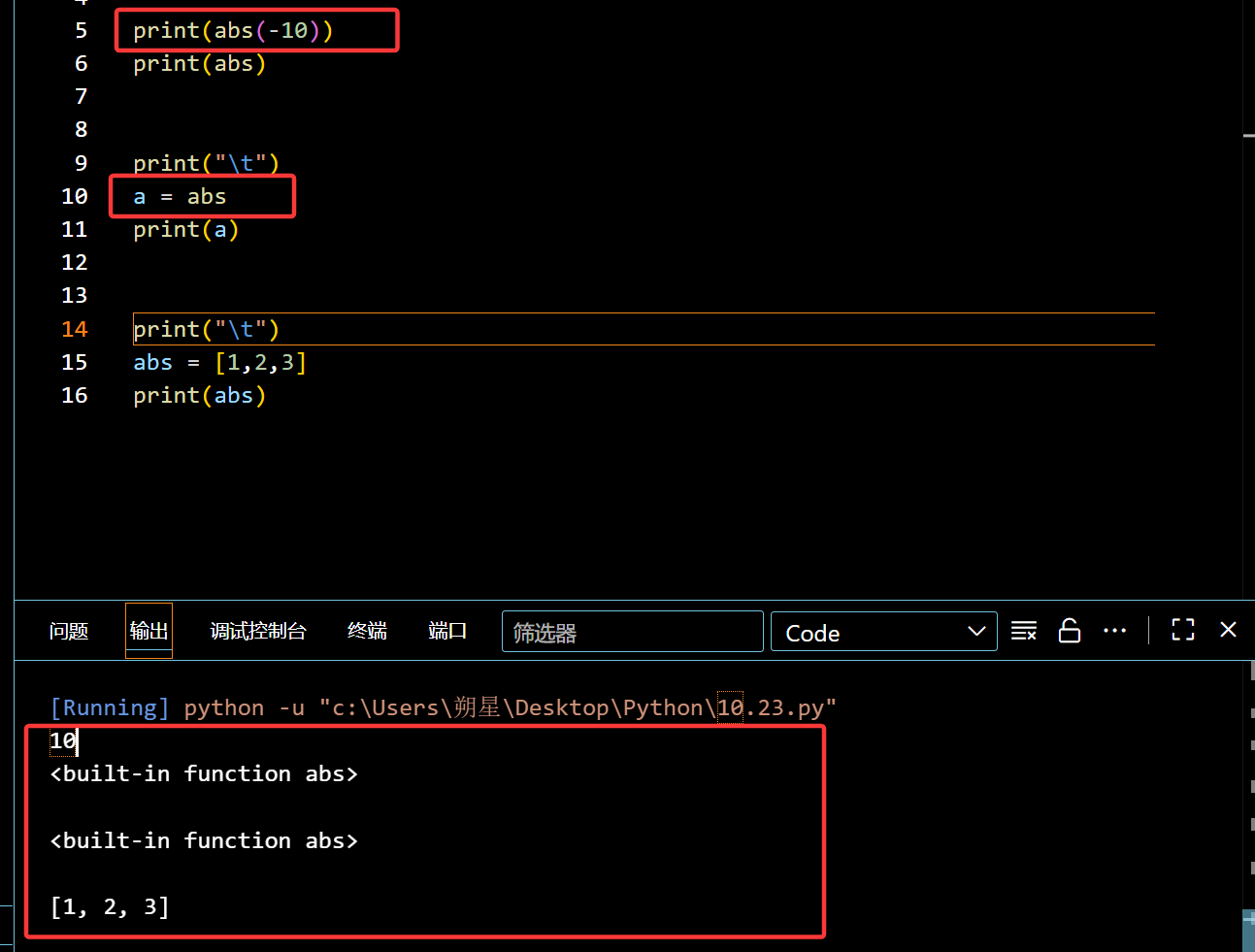
自定义函数可以嵌套其他函数:
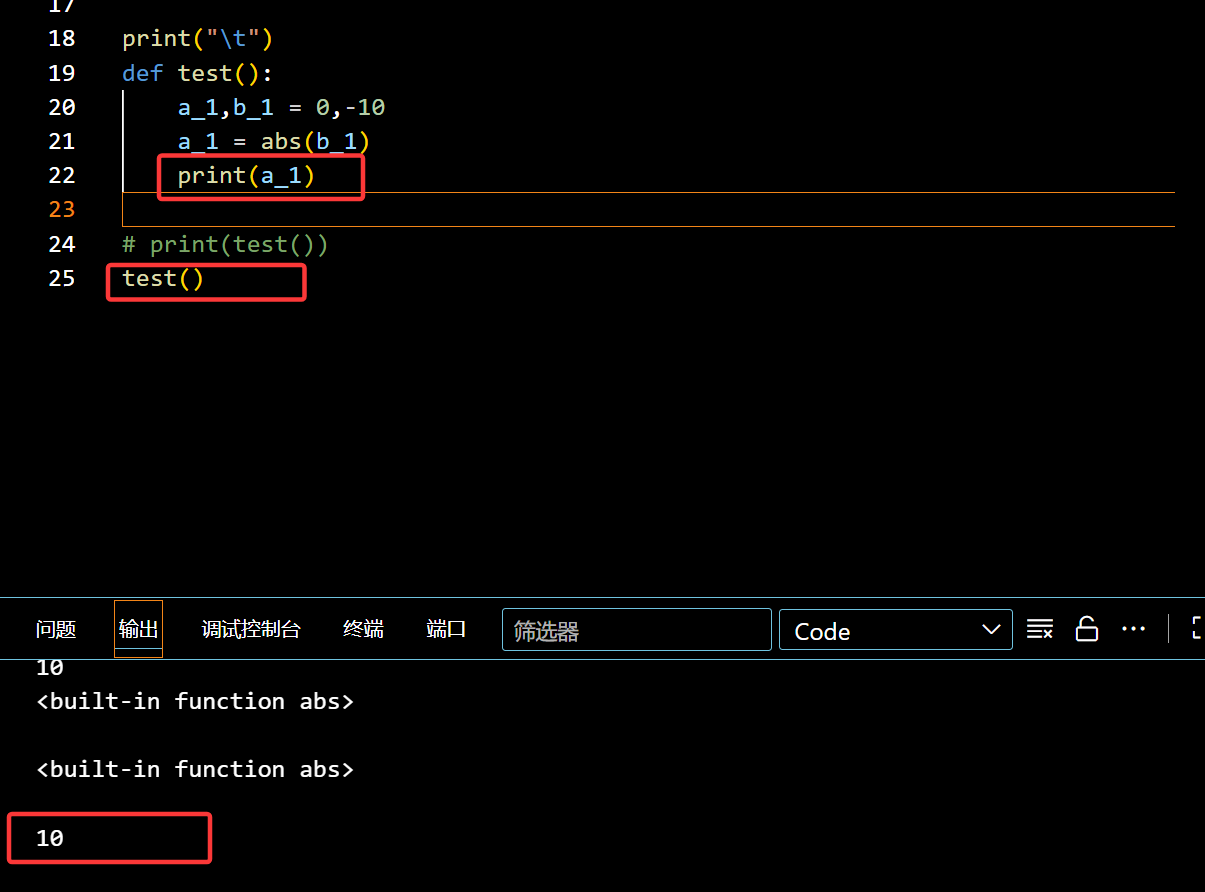
成功调用 abs 用在 test() 函数中
备注:
函数使用 return 和 print 的区别:
1 | def test(): |
1 | def test(): |
Map (高阶函数)
作用:直接把 Iterable (比如 list ,dict ) 和低阶函数进行运算
特性:
1 | a = [1,2,3,4,5] |
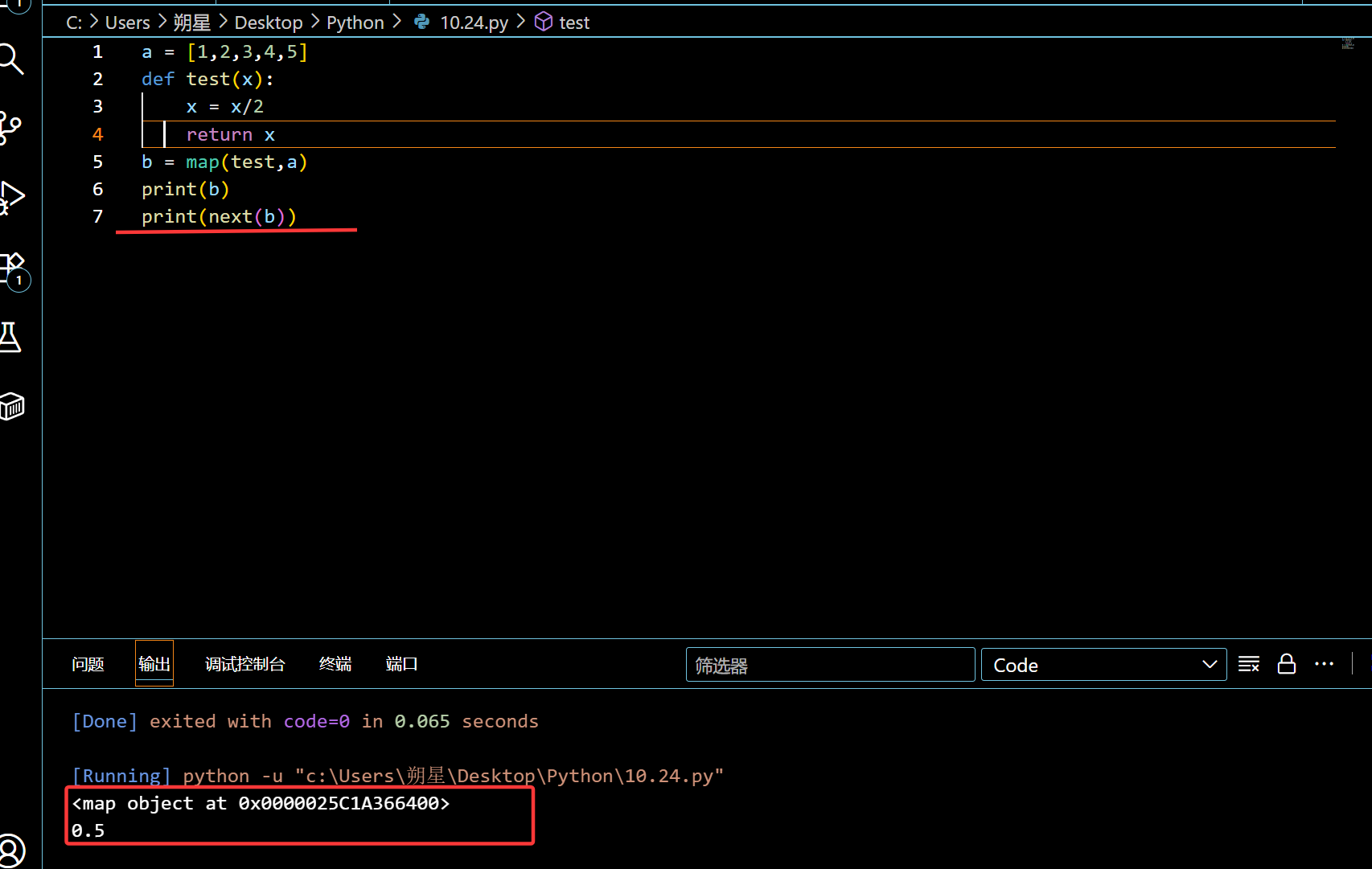
1 | a = [1,2,3,4,5] |
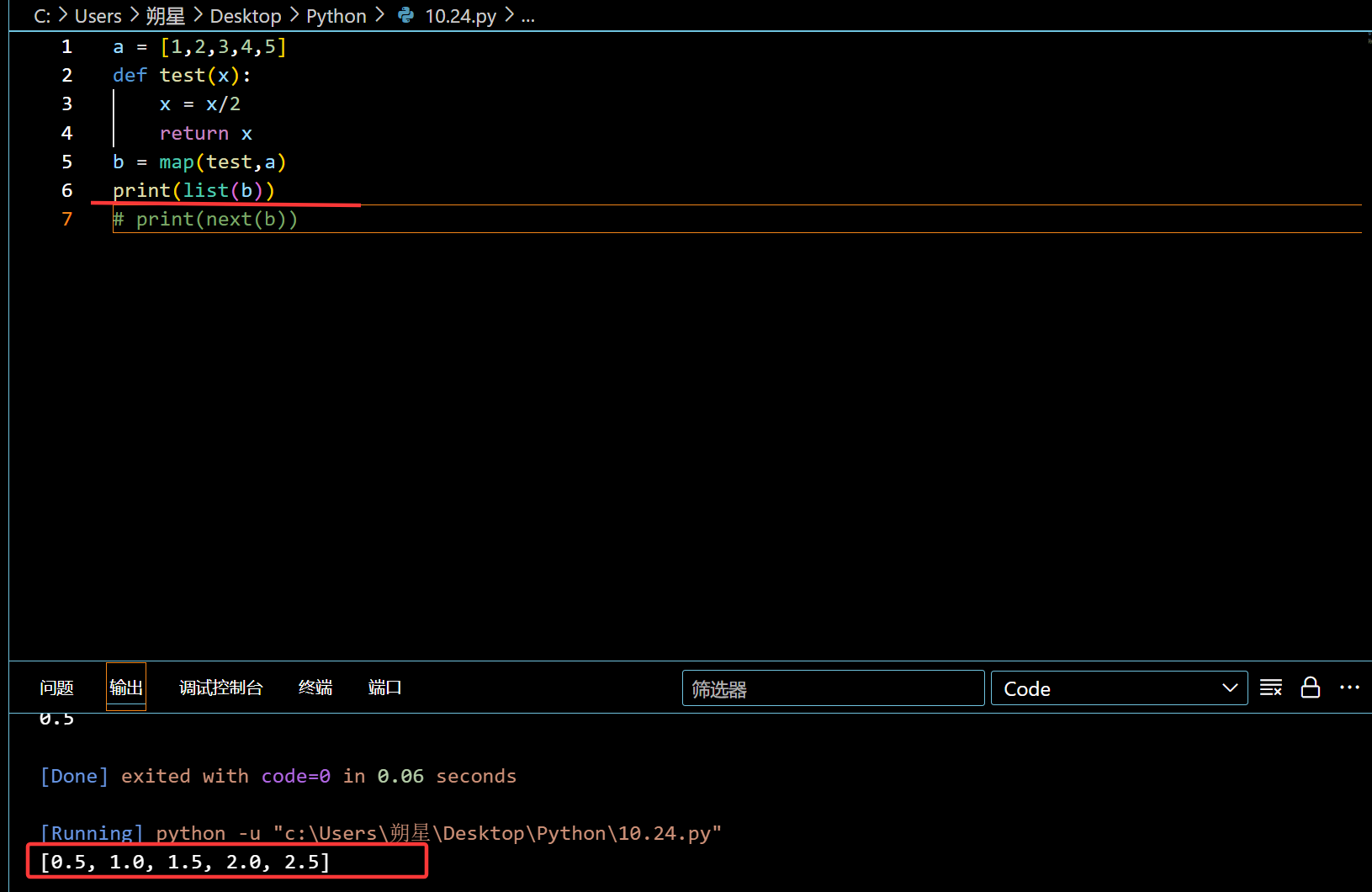
这样子可以快速调用函数,不用使用 for 循环。
filter
和map一样,接受 ( 函数 + iterable )
作用:会把 iterable 里面的数值带入 函数 ,如果是?Ture就删去,只留下False(最后会形成迭代器,得用 list 来转化)
1 | def is_odd(n): |
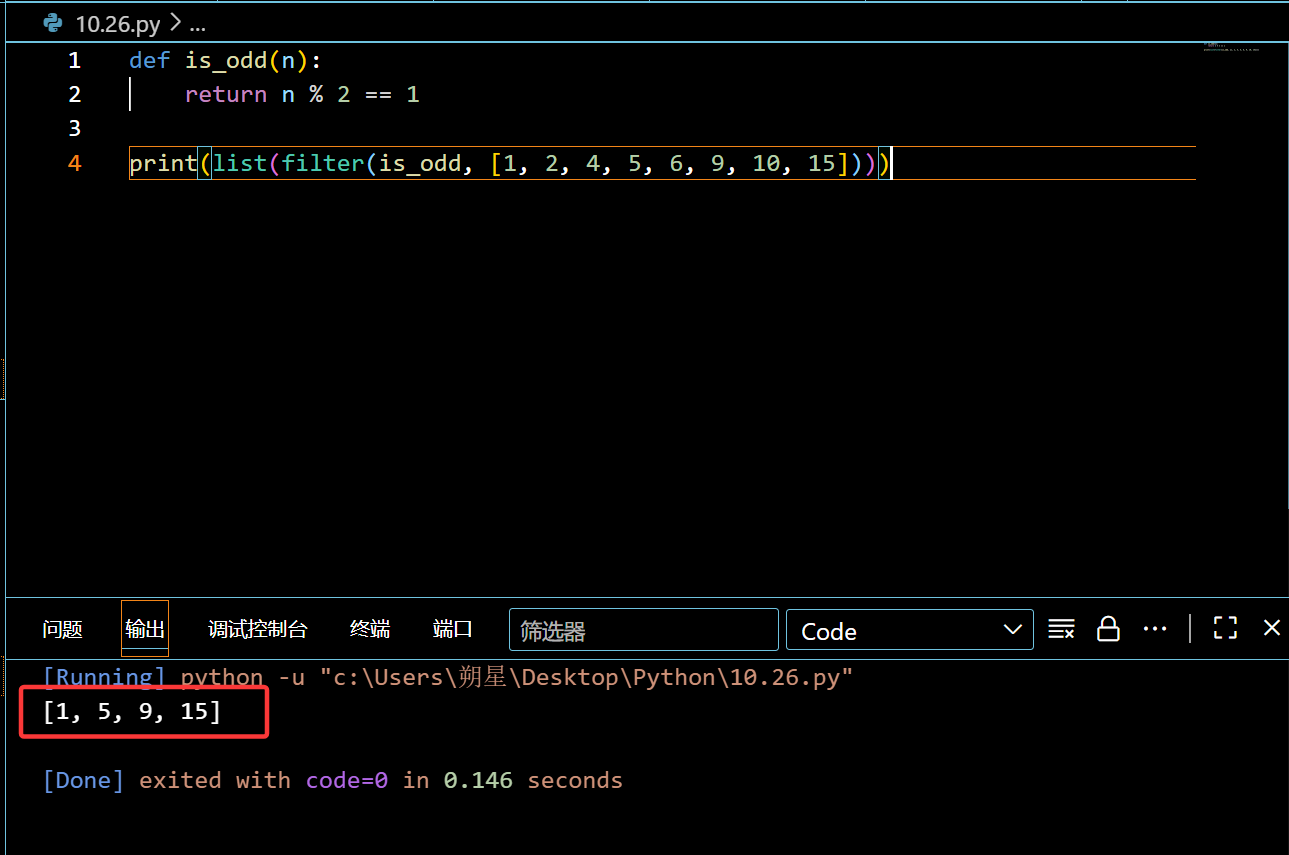
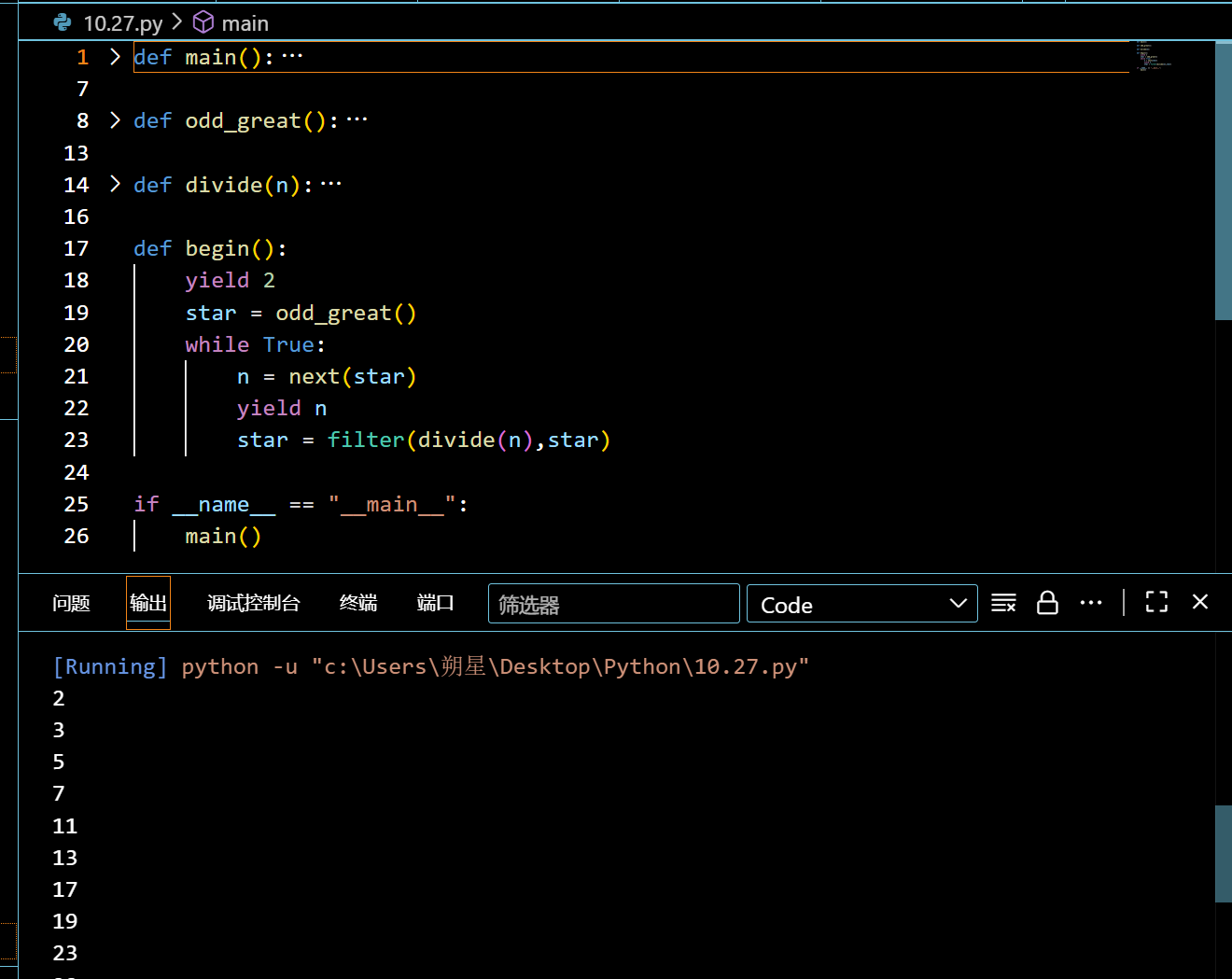
实例函数:(素数创建)
1 | def main(): |
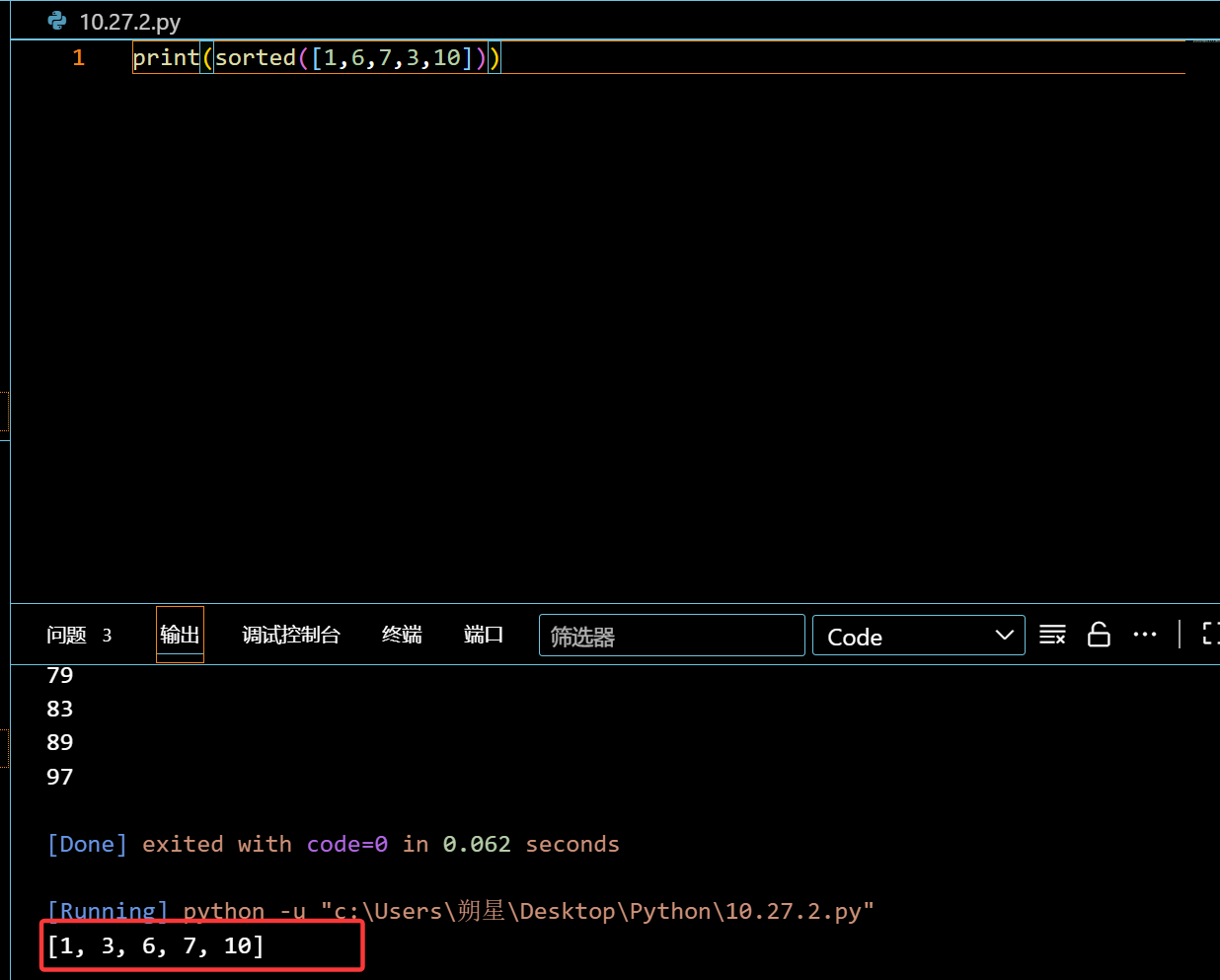
sorted:自动排序 (从小到大)
1 | print(sorted([1,6,7,3,10])) |
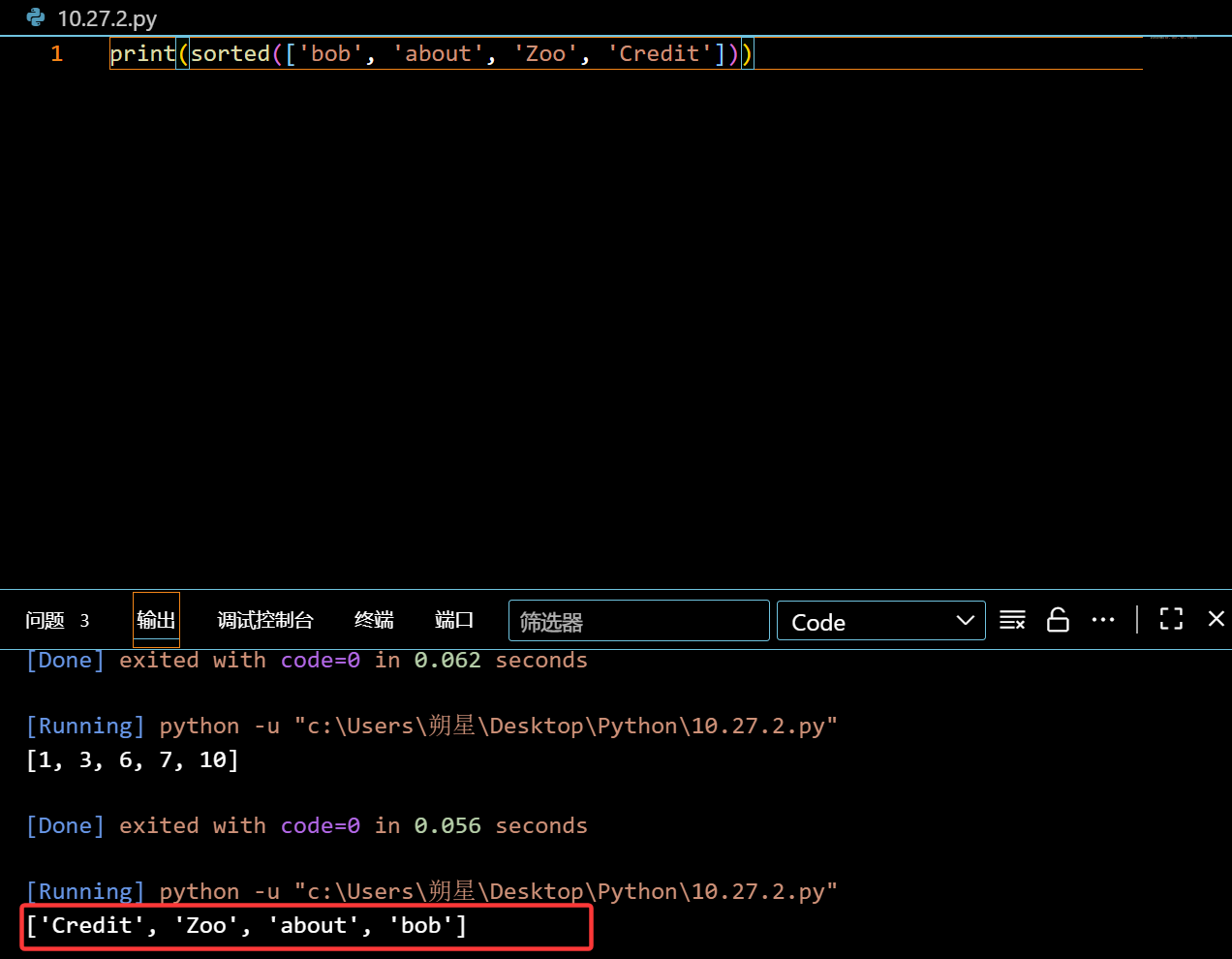
字母的话,则是第一位数:
1 | print(sorted(['bob', 'about', 'Zoo', 'Credit'])) |
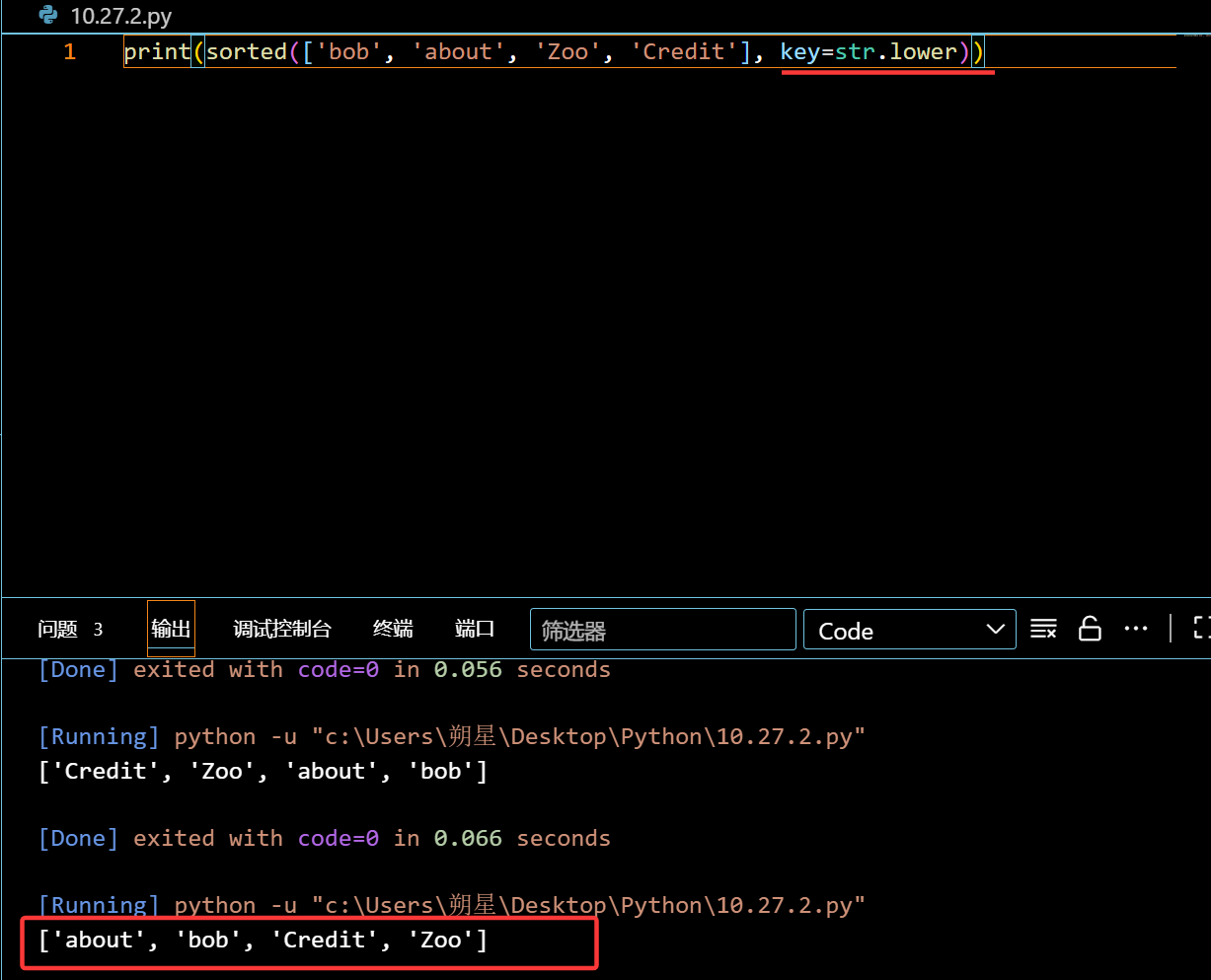
后面也可以跟一个函数,来先执行函数,再进行比大小:(key=函数)
1 | print(sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower)) |
返回函数:
函数嵌套函数:(闭合)
1 | def step_1(x): |
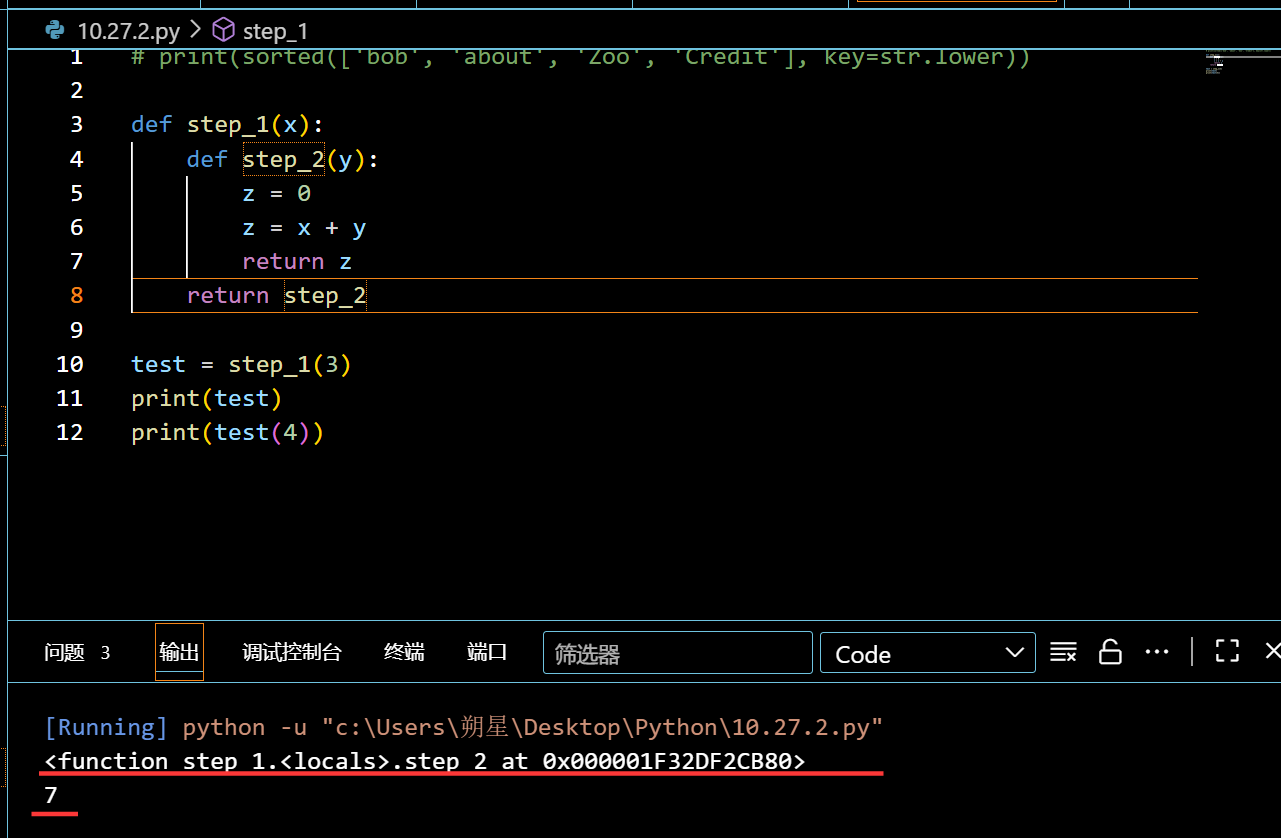
第一次给 test 赋值的时候,会返回 step_2 这个函数,且此时会记住 x 的值,再次给 test 赋值的时候,就相当于给 step_2 赋值了,所以就可以获取到想要的结果了。
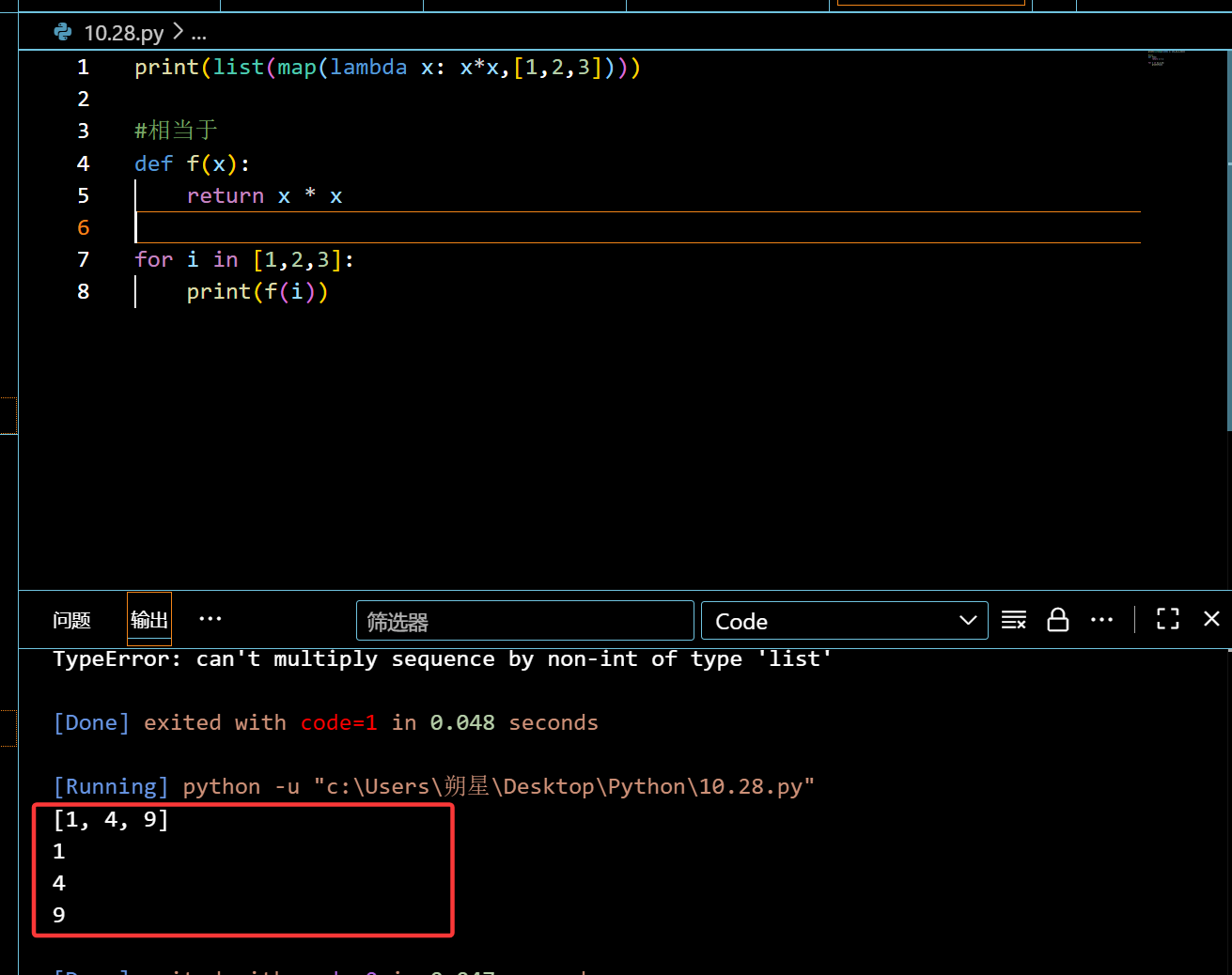
匿名函数:(lambda)
1 | print(list(map(lambda x: x*x,[1,2,3]))) |
也可以写成返回函数:
1 | def build(x, y): |
相当于:
1 | def build(x, y): |
调用模块
模块本质上就是一个一个 py文件
标准模板:
1 | #!/usr/bin/env python3 |
引入模块:
1 | import hello #如果刚才那个文件被命名为 hello.py |
调用区别:
1 | _name #一条下划线:建议不要调用 |
魔术方法:(预制菜)
1 | __file__:返回当前模块(.py 文件)的绝对路径或相对路径 |
类:
定义:
就是人工预制,在一个类里可以自己设定几个功能:
1 | class student(): |
怎么调用:
1 | stu_1 = student("朔星",114514) #先创建一个对象,给他赋值 |
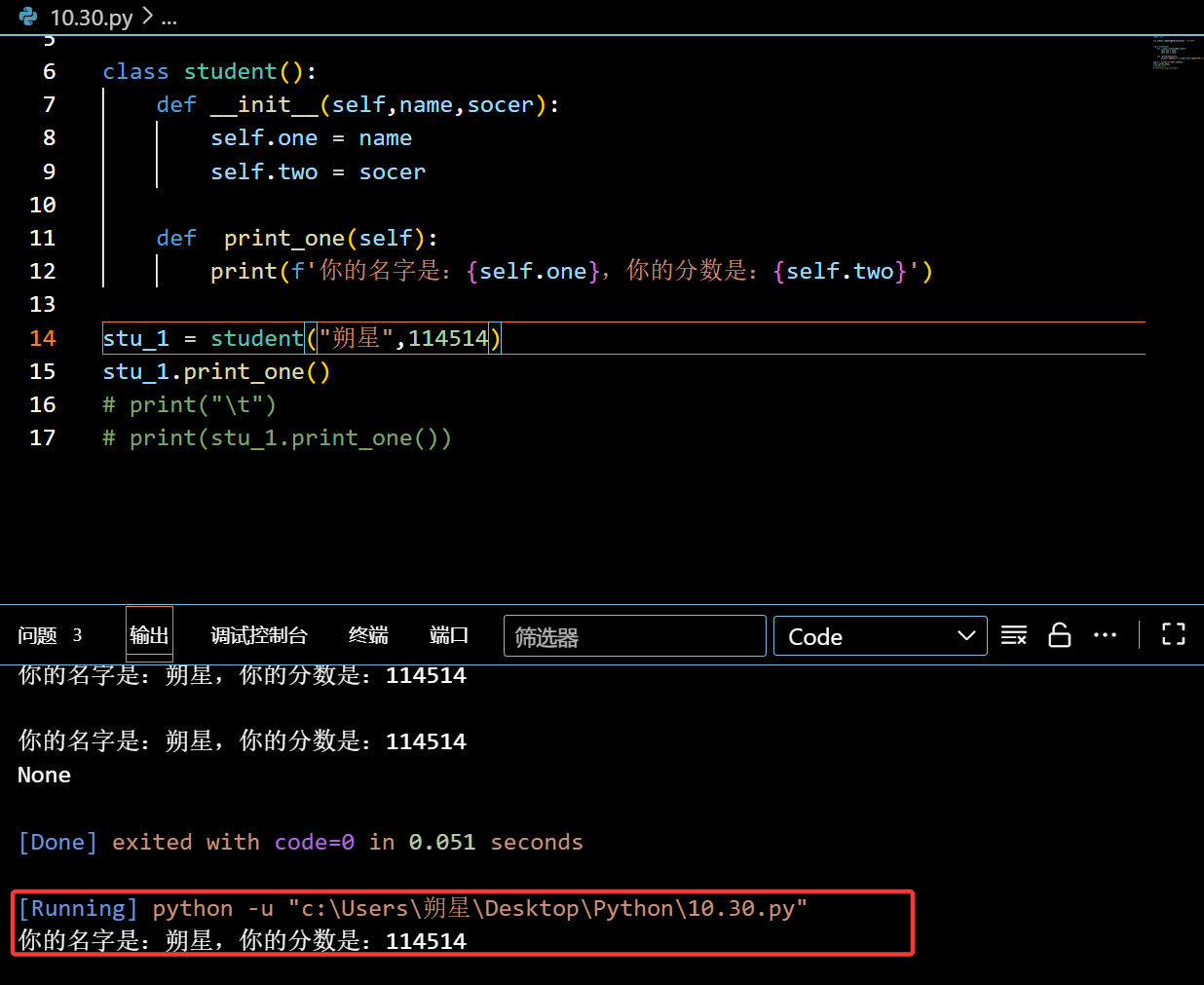
也可以自由赋值:
1 | stu_1.thd = 111 |
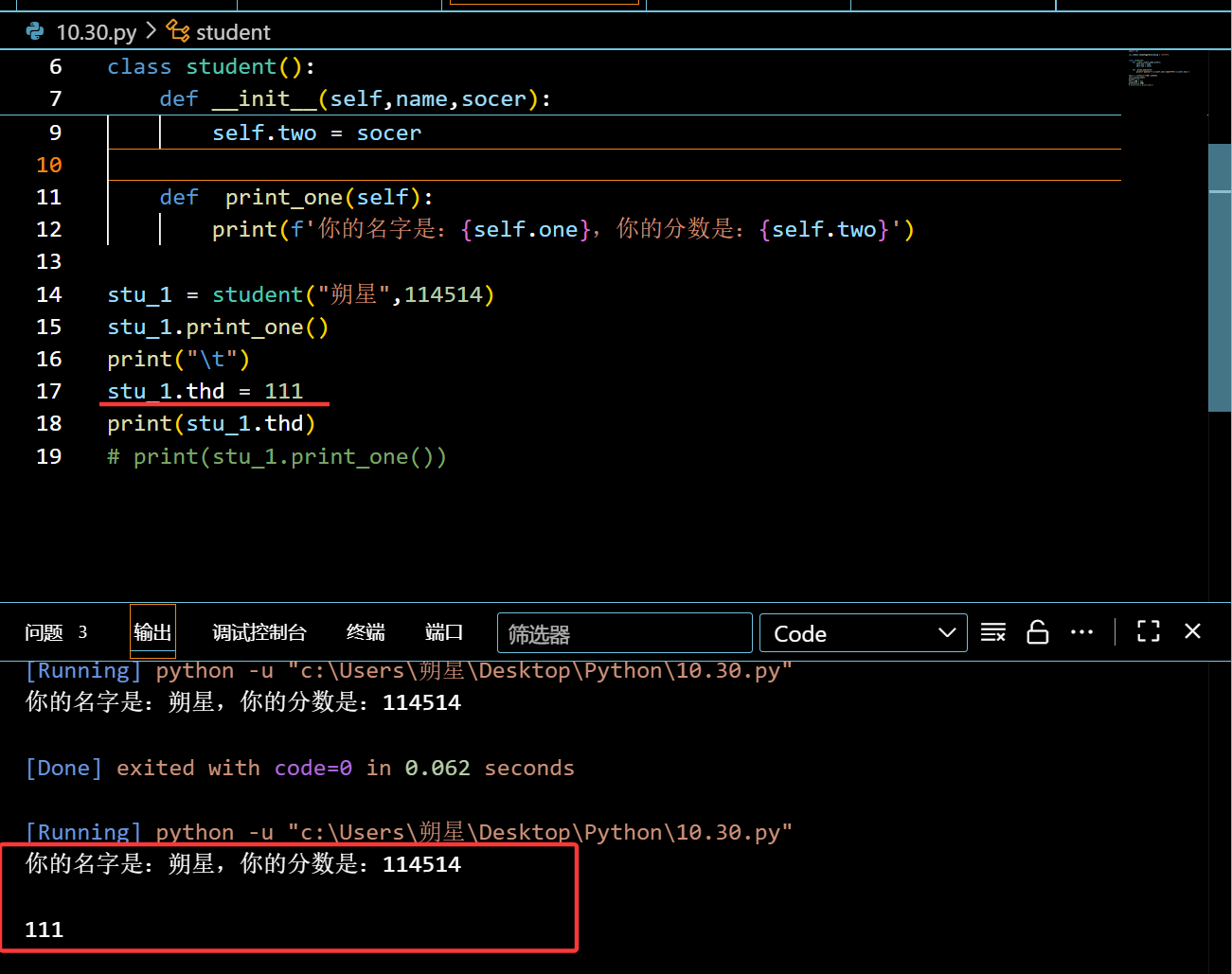
外部是否能正常访问:
1 | class Runnable(object): |
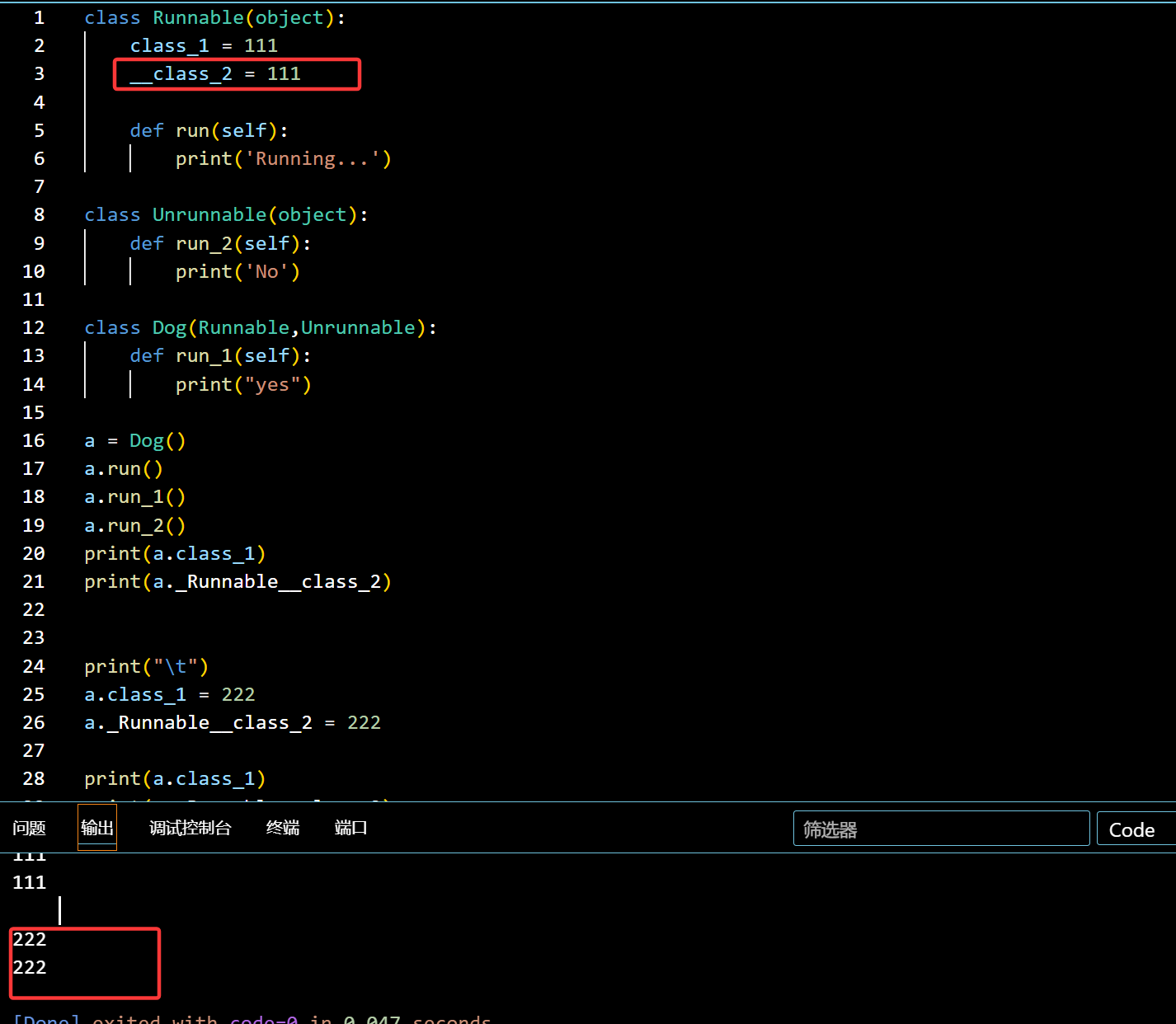
虽然是私有的,但是只要前面加上了类的名字,还是能成功修改的
完全无法修改:(@property)
1 |
enumerate函数:
直接读取目标列表中的值并且赋值,用于循环:
1 | nums = [2,7,11,15] |
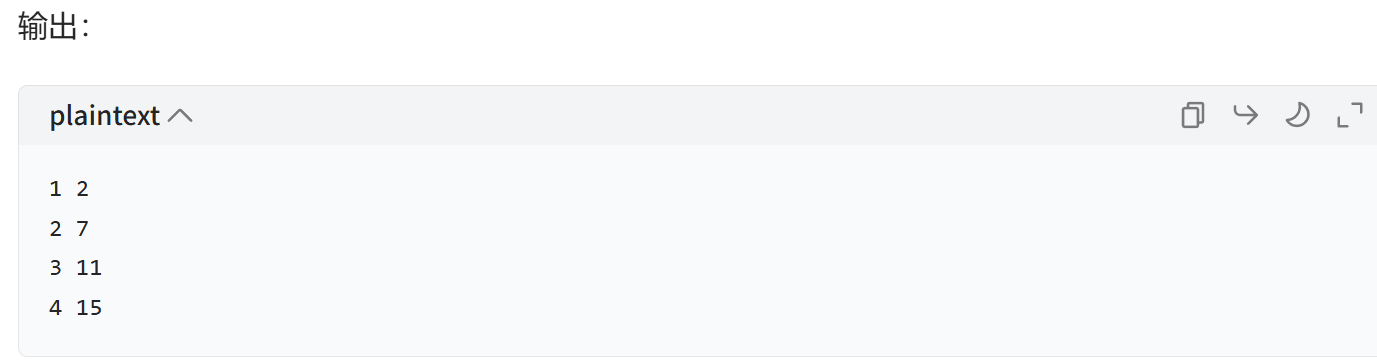
可以对类直接添加方法:
1 | import sys |
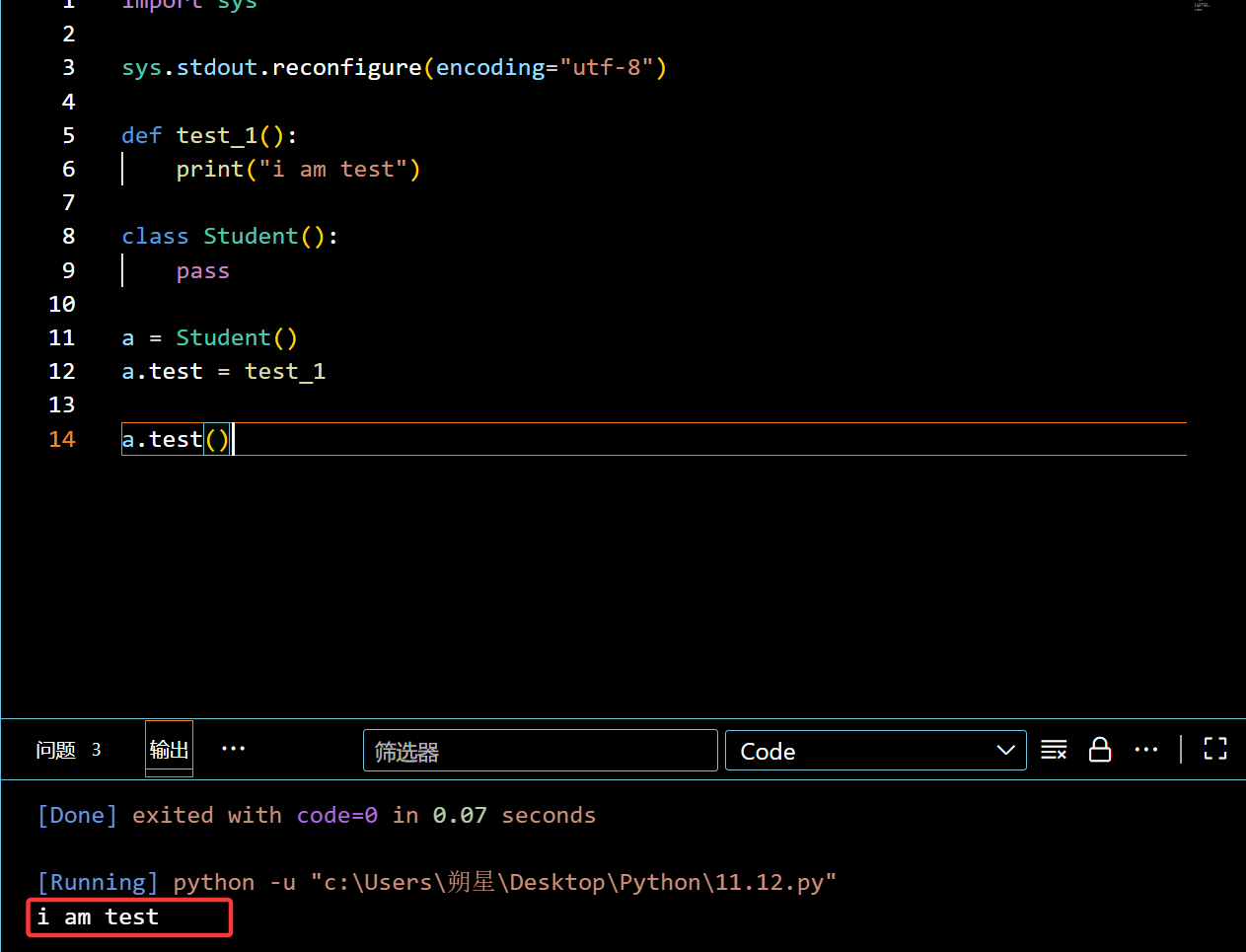
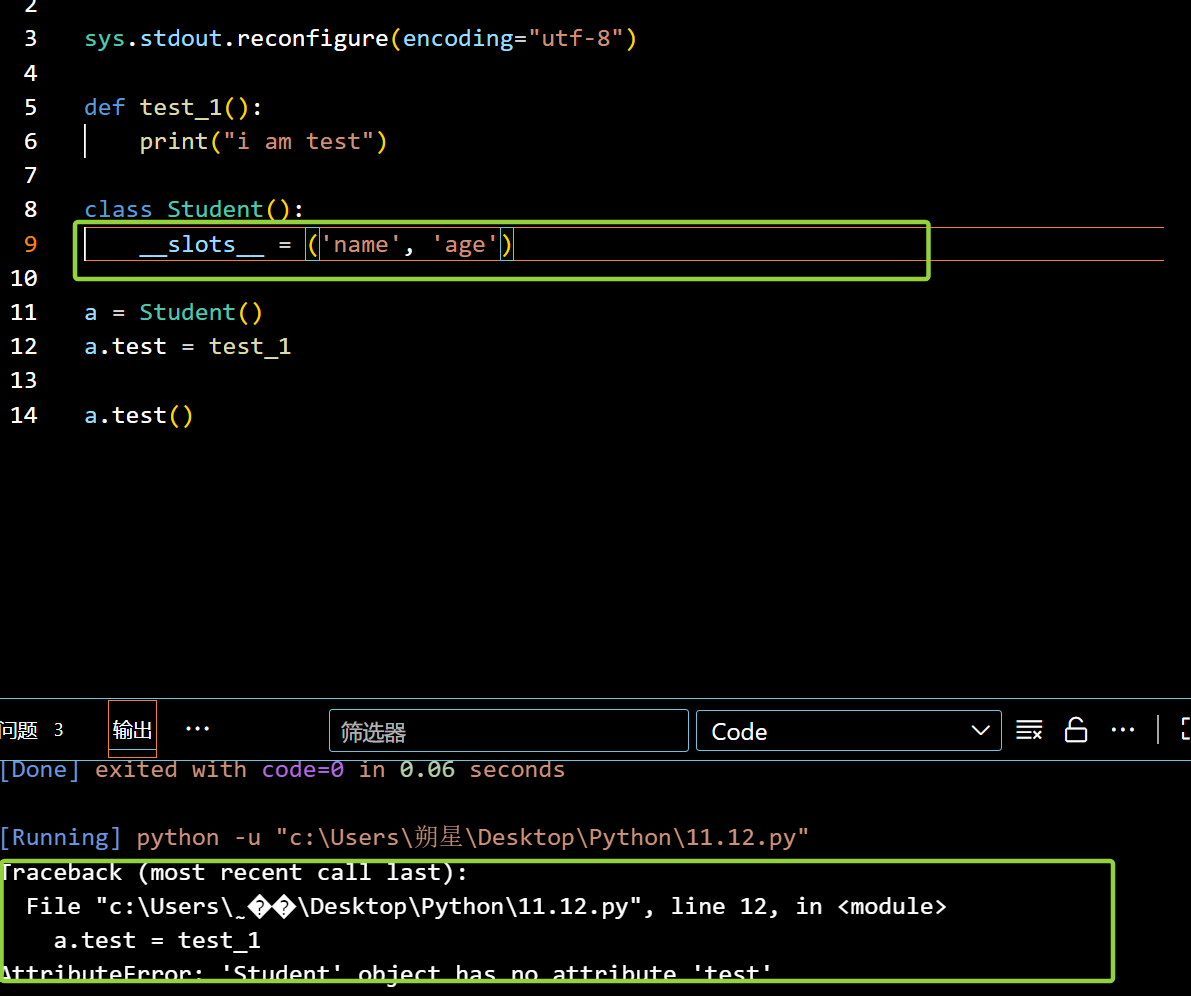
在外部对类的添加加上限制:(__slots__)
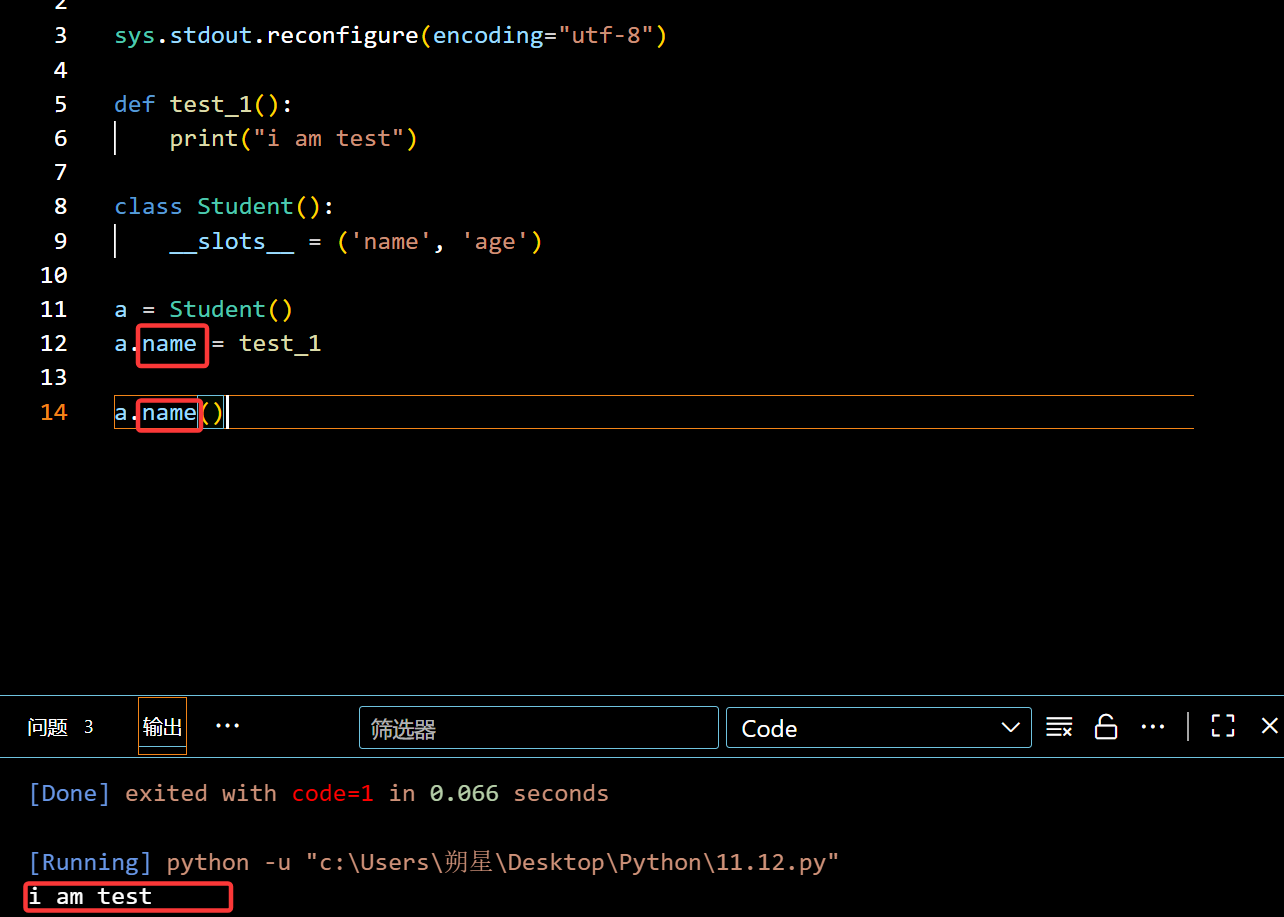
1 | class Student(): |
1 | class Student(): |
装饰器:(@property + self)
@property:
用于让方法变成属性,不需要 () 也能调用
1 | class test_1(): |
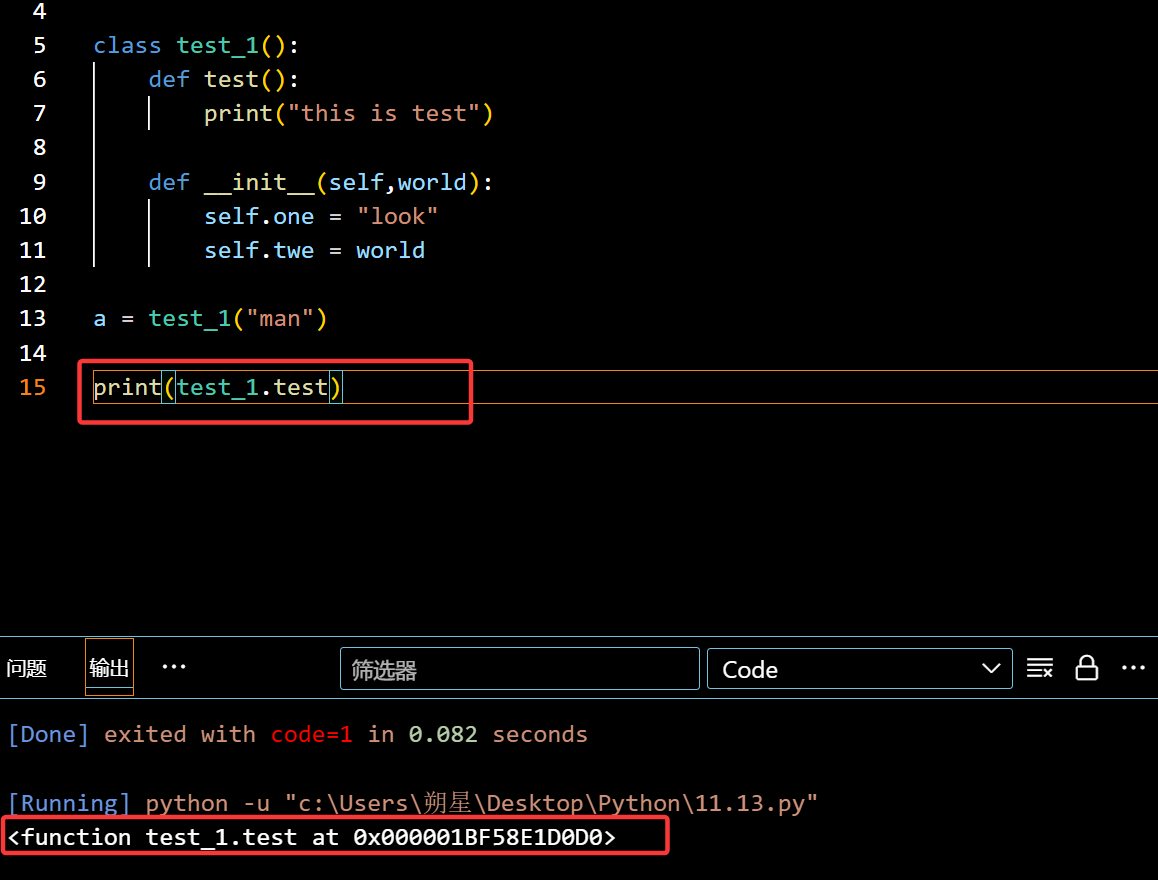
没有修饰词,此时直接调用(没加 () )就只会显示地址
这里错了,应该是引用a,而不是直接引用 类
报错:(没在目标加入self)
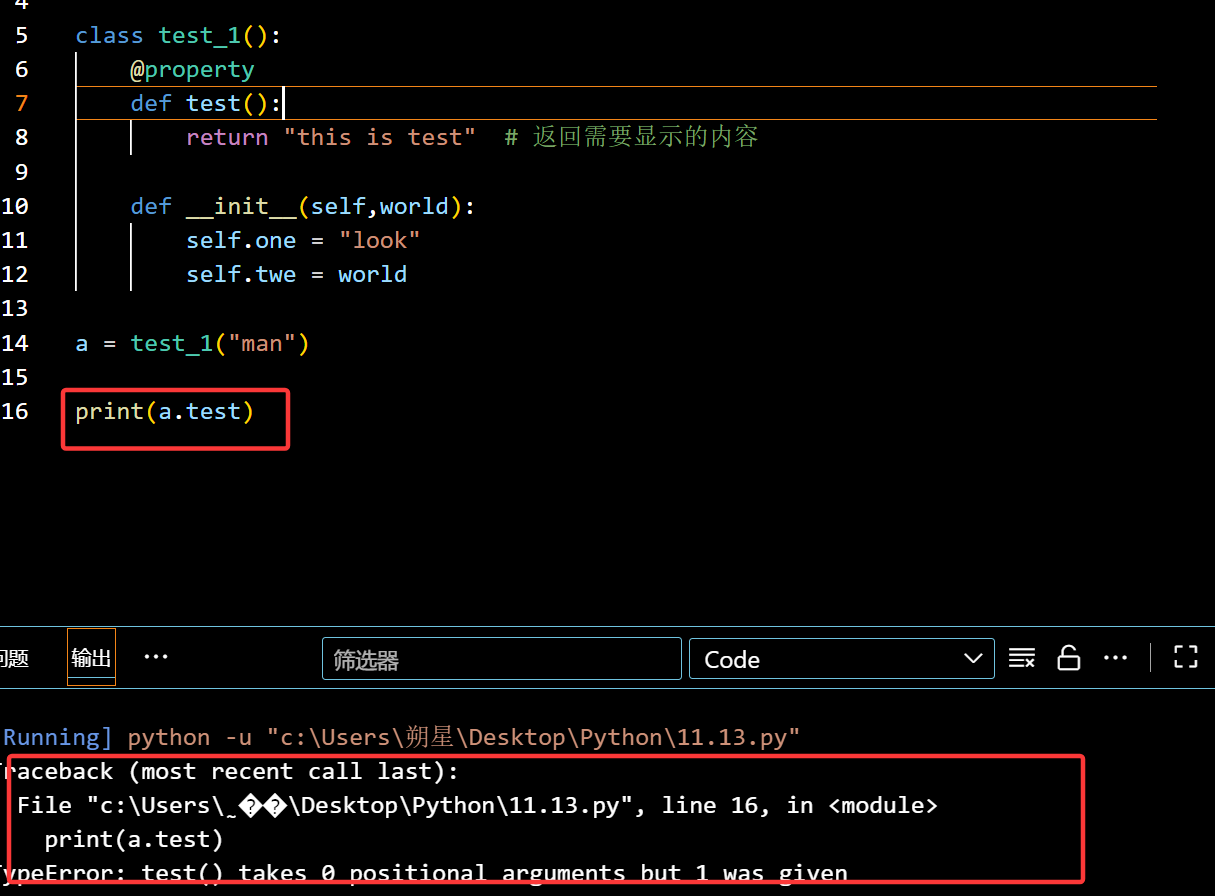
正确:
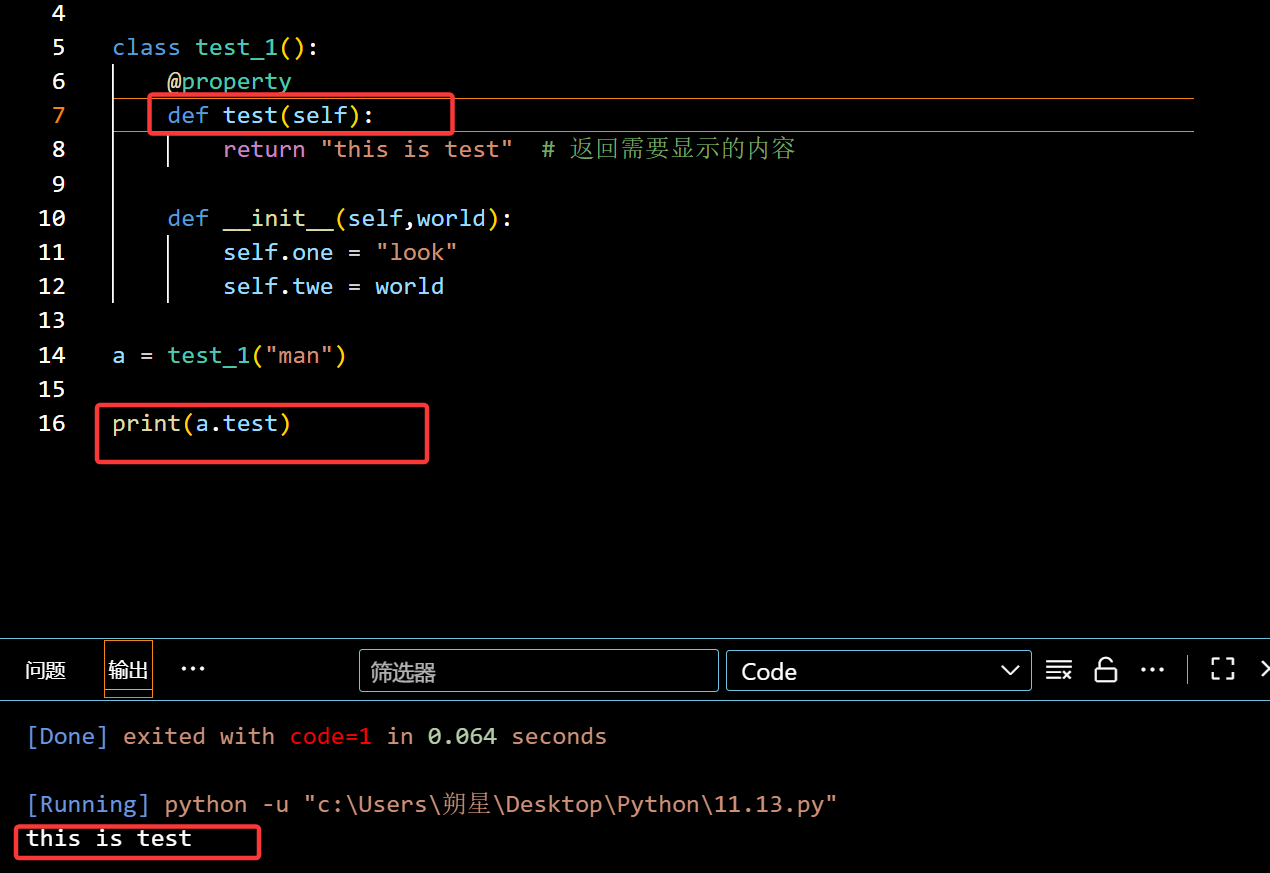
装饰器:(@属性名.setter —》 附属装饰器)
定下限制规则的装饰器
1 | class Student(object): |
